


Everything Everywhere All at Once: Embodied, Distributed, Nature-inspired AI #10
Plus, an alarming decrease in global biomass of wild mammals, a huge leap by Neuralink, SpaceX, and the surge of RE.


Let’s be real — the 2020's have been a wild ride, and we're not even halfway through the decade yet. It feels like a long, weird dream that just keeps getting weirder by minute.
When COVID-19 hit us like a ton of bricks, it turned the world upside down. One minute we're living our best lives, and the next, we're stuck at home, watching our reality warped into something straight out of a sci-fi thriller. But just when it seemed like all hope was lost, humanity bounced back like a champion. Scientists worked around the clock to create vaccines in record time, and before we knew it, we all survived with flying colors.
It felt like a major setback, but little did we know, it was just the universe's way of propelling us forward — somehow. It seems the past few years have sent us on an accelerated progress slope, with each week bringing something crazier than the last.

Let's start with the fact that in just a few short years, we've gone from Siri struggling to understand our accents to Google’s Gemini, Claude 3 Opus, and OpenAI’s GPT-4 writing poetry, solving complex math problems, and even coding.
This week, that accelerated progress is becoming more apparent. It’s like everywhere, everything, all at once is accelerating. At this point, I could woke up one morning and suddenly the robots were smarter than me… and I think that day has come.
#1. Embodied AI: When ChatGPT has a Body

Current AI is trapped in the digital prison. As impressive as the recent advancements in AI are — especially on the LLMs front, they are static and unable to evolve with time and experience. It’s like they're stuck in a never-ending Zoom call: no physical presence, just cold 1s and 0s bouncing around aimlessly. And we all know how much fun those are.
Think about it: what makes humans and animals intelligent? It's not just our ability to reason and spit out coherent sentences (even animals don’t have language). It’s the combination of three key ingredients: the mind to think, of course, also the ability to perceive the world through senses, and then take action based on those perceptions (Kirchhoff et al., 2018). Essentially, we gotta be able to learn and dynamically update our beliefs through lived experiences. Sure, we can think of LLMs as a “mind”, but they’re missing those other essential parts — no physical embodiment to sense the world, and no way to impact their environment through action (unless installing mind virus to your brain counts). LLMs are basically just… floating brains in the metaverse. And that’s not even real.
In sci-fi films, AI always seems to come packaged in some slick android body or robot form. And that’s for a good reason: real-life actions. Some companies like Google, Microsoft, Tesla, Boston Dynamics, and others are working toward giving AI models a body — this is called "embodiment". Recently, the new kid on the block, Figure 01 (and yet again, powered by OpenAI) shocked the world with a demo, showing off its housekeeping skills like putting away dishes, cleaning out trash dumped, and more.
What’s special about Figure 01 is that its integration of physical and cognitive abilities. While Tesla’s Optimus has AI capabilities — and developing — it hasn’t reached the level of conversation and higher-level reasoning seen in Figure 01. And while RT-2 (Google’s) is a powerful vision-language-action models, they still lack the physical embodiment that Figure 01 has. In the above video, we can also see that Figure 01 demonstrates complex multi-step instructions, physical dexterity, as well as switching between tasks with fluidity. It can also explain its actions while simultaneously performing them, suggesting an impressive level of parallel processing. This kind of adaptability is crucial for working in unpredictable human environments.
The idea is that Embodied AI (E-AI) could bridge the gap with physical senses, bringing it into the world and experience it through sensors, sights, sounds and all. As we know, Autoregressive LLMs are not designed to understand the causal relationships between events, but rather to identify proximate context and correlations within sequences. But a truly intelligent, embodied agent should be able to grasp the underlying causality behind events and actions within its environment, be it digital or physical. With that deeper comprehension of cause-and-effect, these embodied agents could then make informed decisions based on the likely outcomes — kind of like when us biological beings weigh the pros and cons before taking an action. So in that sense, modern LLMs could be one of the foundational building blocks. This approach is akin to how newborn babies come into the world equipped with inherent priors to successfully adapt to the world (Reynolds & Roth, 2018). As demonstrated in the above video about Figure 01, language abstractions can enable efficient learning and generalization. Once learned, language opens the door to planning, reasoning, and communicating effectively about grounded situations and task.
In fact, Google has paved the way towards this vision since a couple years ago when they bring the capabilities of LLMs to robotics. They improve it further through RT-2 and shown that vision-language models (VLMs) can be transformed into powerful vision-language-action (VLA) models, which can directly control a robot by combining VLM pre-training with robotic data. And built upon these findings, DeepMind harnessed it further through their recent works: AutoRT, SARA-RT, and RT-Trajectory. Through Open X-Embodiment: Robotic Learning Datasets and RT-X Models, DeepMind partnered with 33 academic labs and pooled data from 22 different robot types to create some kind of a “foundation” model that can control many different types of robots, follow diverse instructions, and generalize effectively — pushing the boundaries of what’s possible.
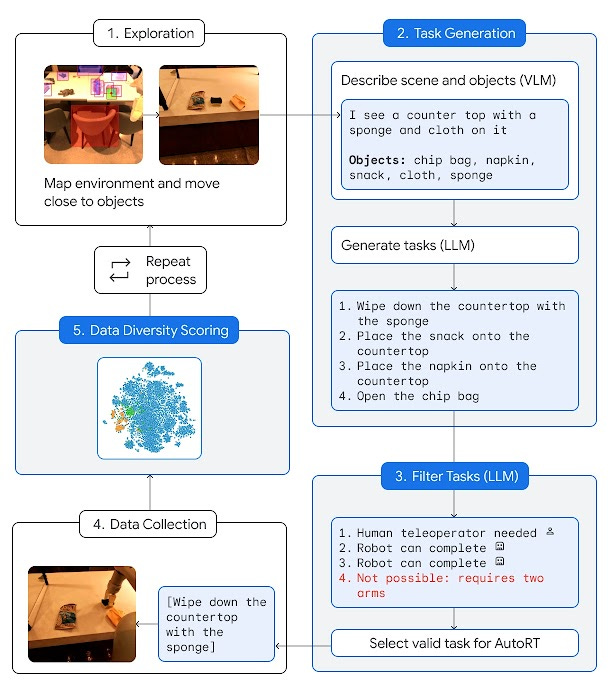
DeepMind is taking it to the next level. They recently introduced The Scalable, Instructable, Multiword Agent (SIMA) project that aims to create an AI system that can understand and follow any language instructions to perform actions in various virtual 3D environments, ranging from custom research environments (Playhouse, Construction Lab) to a wide variety of commercial video games (No Man’s Sky, Valheim).
Drawing inspiration from the success of large language models i.e training the model with a broad range of data to advance general AI, SIMA’s focus is not (only) about achieving high game scores, but to create a versatile, generalist AI agent that can adapt to different environment and tasks. What’s also interesting from SIMA is that, the agents use the same keyboard-and-mouse controls that human do (e.g., Baker et al., 2022; Humphreys et al., 2022; Lifshitz et al., 2023), rather than handcrafted action spaces or high-level APIs; This way, SIMA can be plugged into any new digital environment without needing to redesign the whole controls and UI from scratch.
DeepMind surely isn’t the only one making waves with their embodied AI research. Most notably, the GPU giant, NVIDIA has been creating such a system but only focus on Minecraft game as its environment [MineDojo] and recently through [Voyager] they focus on building a “lifelong learning” agent that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Akin to a teenager on a gap year to find itself, but instead of backpacking through Europe, it’s traversing and learning in the digital world.
And NVIDIA seems to be doubling down on this front. They’ve setup a whole new research lab called GEAR LAB (Generalist Embodied Agent Research), and this comes as no surprise since they’ve had previous successes: NVIDIA Robotics platform adoption reached more than1.2 million robotics developers.
At the recent GTC (GPU Technology Conference), NVIDIA dropped some serious bombshells and announced Project GR00T (Generalist Robot 00 Technology), a general-purpose foundation model for humanoid robots. Like a robot’s AI brain, GR00T allows for rapid skill acquisition and problem-solving on the fly. Nvidia also gave their Isaac Sim robotics platform a major upgrade. This platform allows robots to learn physical interactions at an accelerated rate in thousands of parallel simulated physical environments. The updates include "Isaac Lab" for reinforcement learning, OSMO for compute orchestration, and collections of robotics pretrained models and libraries called Isaac Manipulator and Isaac Perceptor. Isaac Manipulator offers AI capabilities for robotic arms, while Isaac Perceptor provides multi-camera 3D vision capabilities for manufacturing robots.
And as part of the GR00T initiative, NVIDIA also introduced their Jetson Thor computer for humanoid robots based on the NVIDIA Thor system-on-a-chip (SoC). The SoC includes a next-generation GPU based on the NVIDIA Blackwell architecture with a transformer engine delivering 800 teraflops of 8-bit floating point AI performance to run multimodal generative AI models like GR00T. With an integrated functional safety processor, a high-performance CPU cluster and 100GB of ethernet bandwidth.
NVIDIA is proving that they're ready to take on the world of embodied AI, one virtual block and robotic arm at a time. And with all these tools and resources at their disposal, who knows what kind of crazy, world-changing AI they'll cook up next?
And speaking of cooking.. I’ve been thinking about the future of embodied AI, especially when it comes to humanoid bots like Figure 01 and Tesla’s Optimus. Even Elon Musk seems a bit unsure about where this is all heading. He mentioned that Optimus could become a super-advanced household appliance in a few years, but I'm not entirely convinced. I mean, think about it - when was the last time a groundbreaking technology started in the kitchen? 🤔 let alone it would cost more than $10,000. Although the idea of a robot sous chef is pretty cool.
Now, let’s take a step back and look at the bigger picture. I think the real potential of embodied AI lies in its ability to work together in a distributed network. Which brings us to the second topic…
#2. Distributed AI: Decentralized Training and Swarm Intelligence
Imagine a world where humanoid bots like Figure 01 and Optimus aren't just isolated entities, but part of a vast, interconnected web of AI agents. Each bot could be like a node in a giant, global brain, sharing information, learning from each other's experiences, and collaborating to tackle challenges that no single machine (or human) could ever hope to solve alone — that’s basically the concept of Distributed AI.
Now, as we know from the Scaling Law, the current progress in machine learning and AI has been mostly driven by throwing more FLOPs on larger neural network models, and feeding them with bigger data sets. To make this scaling possible, we come up with all sorts of tricks, like data and model parallelism (Dean et al., 2012), and pipelining (Narayanan et al., 2020). These techniques allow computation to be distributed across a huge number of devices, pairing with model architectures (Lepikhin et al., 2021; OpenAI et al., 2023), that enables computation parallelism. However, the core training paradigm hasn’t really evolved to embrace distributed training fully. The state-of-the-art models are still basically monoliths — that require a constant back-and-forth of parameters, gradients, and activations at every step of the learning process. Which is not exactly efficient. It's like trying to coordinate a massive group project where everyone's working on different parts, but they all need to constantly chat with each other to stay in sync.

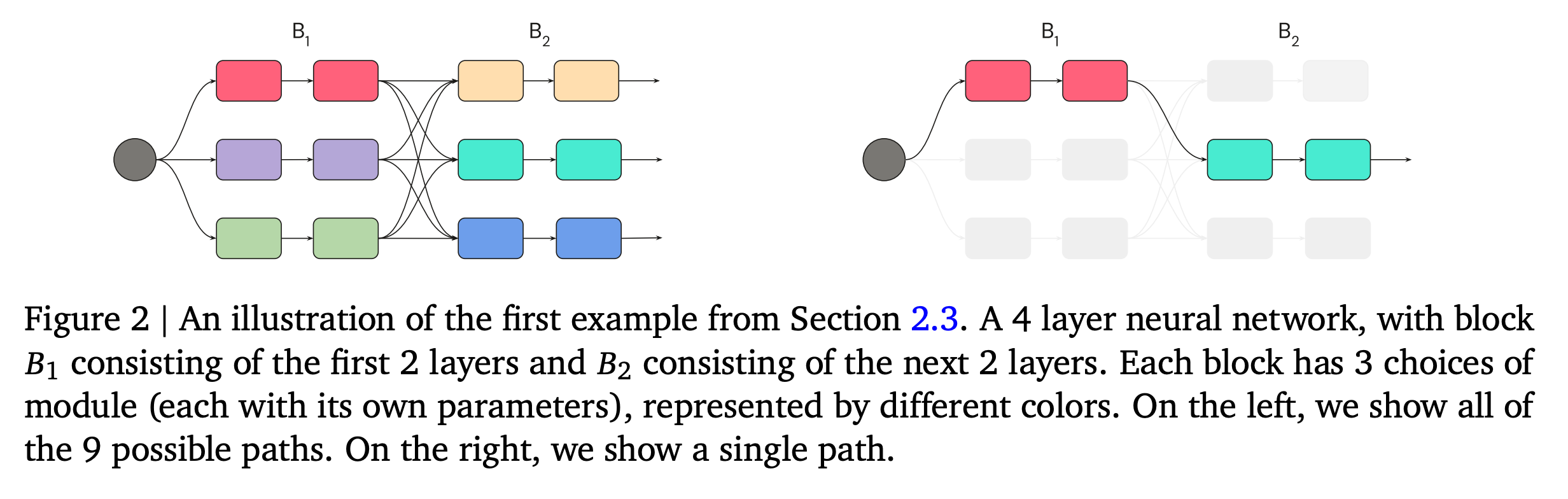
Folks at DeepMind recently published an interesting paper titled “DiPaCo: Distributed Path Composition”, in which they break down training process into smaller modules and allow the model to be trained on different devices with less communication. The high level idea is to distribute computation by “path”, which is a sequence of modules that define an input-output function: basically a mini-model within the bigger model. This way, only a handful of tightly connected devices to train/evaluate needed for each path. At inference, only a single path needs to be executed for each input, without the need for any model compression.
Here’s a TL;DR by the author:
Everything, everywhere, all at once: a experimental mixture of experts that can be trained across the world, with no limit engineering-wise on its size, while being able to be light-weight and fast at test-time — Arthur Douillard
There are two key ideas to making this work:
Coarse Routing: Sparsely routed Mixture of Experts (MoE) have shown great results in language modeling (Lepikhin et al., 2021) — which I also briefly cover in the previous post. The standard approach in a transformer MoE LM is to make a routing decision at each token, based on the feature at each routed layer. Here, DiPaCo instead done the routing per document/sequence level and offline, as in (Gross et al., 2017; Gururangan et al., 2023) to enable batching computation across all tokens of a sequence, without the need to swap modules in and out as a sequence is processed. It works as follows:

Source: Distributed Paths Composition (DiPaCo) [Paper] Feature Extraction: A feature vector is computed for each input sequence based on the first 32 tokens. This feature vector captures high-level information about the sequence and is used to determine which path should process it.
Path assignment: The feature vector is used to assign the sequence to one of the available paths. This assignment can be done using various methods, such as:
Generative routing: Unsupervised clustering algorithms like k-means are used to group similar sequences together and assign them to paths.
Discriminative routing: A classifier is trained to predict the optimal path for each sequence based on its features and the performance of each path on a held-out set of sequences.
Data sharding: Once the path assignments are determined, the input sequences are partitioned into shards, with each shard containing the sequences assigned to a particular path. This allows for efficient distributed training, as each path can process its own shard of data independently.
DiLoCo (Distributed Low Communication): Paths cannot be trained completely independently, because some modules might be shared across multiple paths. To support module sharing across paths, DiLoCo (Douillard et al., 2023) is being used for low communication data parallelism.
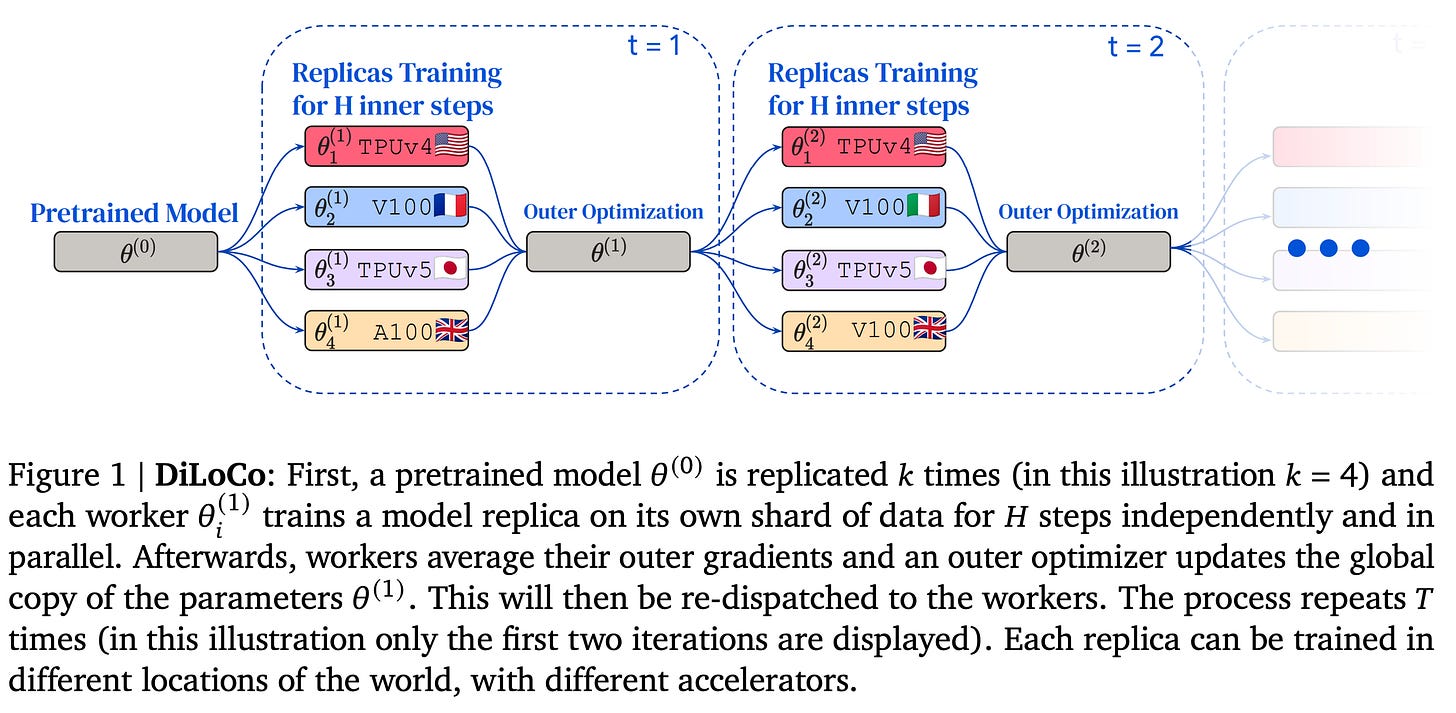
Source DiLoCo paper If there are 𝑃 paths (assigned to 𝑃 workers) that share module 𝑖, each corresponding worker performs SGD on its own shard of data, and every few hundred steps, workers average out the difference in the parameters of module 𝑖 before and after the local SGD phase. These averages are then used to update a global parameter vector which is then re-distributed across the workers to sync them. DiLoCo allows for heterogeneous compute environments, as each path can perform its local updates at its own pace using different hardware.

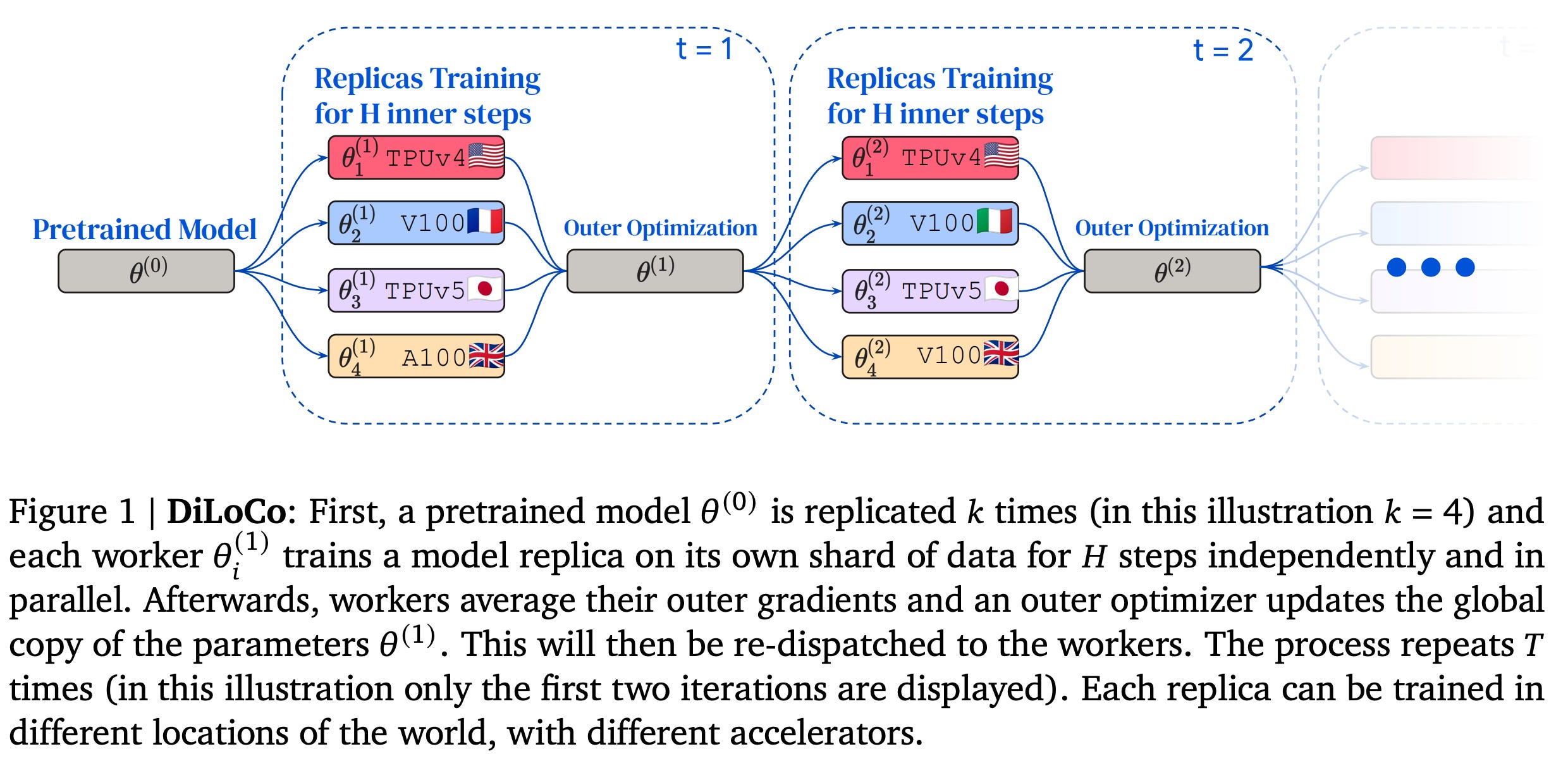

Putting everything together, we get DiPaCo : (left) The dataset is pre-sharded into 𝑘 shards, D𝑖 (here 𝑘 = 4). (middle) Compact view of a 2 × 2 DiPaCo, which is never instantiated. In this toy illustration, there are three levels. Level 2 and 3 have a mixture with two modules each. Level 1 has a single module shared by all paths. (right) We associate each shard D𝑖 to a path 𝜋𝑖 , ∀𝑖 ∈ [1, 4]. In this toy illustration, a path is the composition of three neural network blocks. The color refers to the id of a module. The figure shows the modular network unrolled across the four paths. These are trained by using DiLoCo which requires communicating only every few hundred steps. In this example, module 2a (in red) is shared by paths 𝜋1 and 𝜋2. Workers associated to paths might use different hardware types (different kind of GPUs or TPUs) and might be placed in far away geographic areas. Source: DiPaCo
The combination of these techniques enables DiPaCo to train large, modular models across multiple devices with minimal communication overhead. In experiments, a 16x16 DiPaCo model (256 paths of 150M parameters each) matched the performance of a 1.3B dense model while using 45% less training wall-clock time.
All in all, DiPaCo represents a significant step towards realizing the vision of Distributed AI, where modular architectures and efficient training paradigms allow for the creation of vast, interconnected networks of AI agents. As the field continues to advance, approaches like DiPaCo will play a crucial role in enabling the development of more capable, collaborative, and scalable AI systems.
But the story doesn't end there. Let’s draw more inspiration from the most powerful distributed system of all: nature itself. 🌿🐝
#3. Nature-Inspired AI: Evolutionary Model Merging & Episodic Memory
When it comes to complexity and adaptability, nothing beats Mother Nature. And when we talk about “Intelligence” with a capital “I” — the kind that makes our species the smartypants of the animal kingdom — it’s not just about a single genius brain. It’s about the power of collective intelligence. As also demonstrated in the “Distributed AI” section above.
Let’s be honest: individually, we’re not all that smart or capable (some of us are, but most of us aren’t — myself included). Our societies and economies are basically just a grand collaboration between a diverse individuals with different skills and expertise. It's this incredible collective intelligence that shapes who we are as individuals. Each of us wanders our own little life path, becoming our unique selves, while simultaneously contributing back to the ever-expanding collective intelligence of human civilization. It's a beautiful cycle of mutual growth.
And you know what? I think AI development is going to follow a similar, collectively intelligent path. The future of AI won't be a single, monolithic, all-knowing AI system that uses a lot of energy like a crypto-mining rig. Instead, there will be many different specialized AI systems, each with its own specific purpose or area of expertise., all interacting and leveling each other up. Like the cells in a living organism. 🦠
One fascinating example of this is the work being done by sakana.ai on evolutionary model merging, a general method that uses evolutionary techniques to efficiently discover the best ways to combine different models from a huge library of open-source models with diverse capabilities.
Get this: Hugging Face alone has over 500,000 models spanning dozens of different modalities. That's a massive pool of compressed knowledge just waiting to be tapped into! And with sakana.ai's approach, we can do just that – without even needing any additional training. Model merging allows us to combine task-specific models, each potentially fine-tuned for a particular downstream task, into a single unified model. And in contrast to transfer learning, in which the resulting models are typically limited to single tasks, model merging strives to create a versatile and comprehensive model by combining the knowledge from multiple pre-trained model that can potentially yield a novel model capable of handling various tasks simultaneously.
Brain-Inspired Architectures for Continual Learning
Up to this point, we’ve been discussing about how collective intelligence is important, and the way to achieve it is by distributing the training process, and even combining multiple models to create new ones. However, an equally important challenge lies in keeping our AI models fact-relevant, safe, and ethical after deployment in an efficient manner. A straightforward solution would be to fine-tune the model on corrected/new datasets. Unfortunately, such an approach risks overfitting and catastrophic forgetting (Kirkpatrick et al., 2017; Zhu et al., 2020).
Several lines of research have proposed effective and precise methods for editing large language models (LLMs) (Li et al., 2022; Liu et al., 2023; Zhu et al., 2020). However, these methods often face scalability issues due to overfitting, the need for retraining or locating new states, and high memory requirements for storing numerous edits. These factors can cause significant slowdowns, especially in sequential and batch editing setups.
In a recent paper, researchers from IBM AI research and Princeton University present an intriguing alternative inspired by neuroscience theories on how the brain combines complementary learning systems. Their "Larimar" architecture draws inspiration from the hippocampus (for rapid learning of instances) and the neocortex (for modeling statistical patterns).
Larimar proposes treating language models as the slow neocortical learners, while employing a separate episodic memory module as the fast hippocampal system. This hierarchical episodic memory module allows for rapid, one-shot updating of a language model's knowledge by writing new facts directly into the memory, without the need for expensive retraining.

The updated memory then conditions the language model to output information consistent with the newly written facts. This brain-inspired approach provides an elegant solution to the challenging problem of continual learning and knowledge editing for large language models, all while taking cues from how our own brain solves these problems.
By leveraging insights from neuroscience, the Larimar architecture demonstrates the incredible potential of neurologically-inspired AI architectures. It offers a scalable and efficient method for keeping language models up-to-date with the latest information, without the drawbacks of traditional fine-tuning or editing techniques.
Epilogue
Well, there you have it folks - the future of AI is shaping up to be a really exciting one! I'm talking embodied AI that can physically engage with the world around it, and distributed AI networks that collaborate and evolve like living biological systems. Crazy, right?
As AI continues its exponential growth, drawing inspiration from diverse fields like physics, neuroscience, and evolutionary biology, the boundaries of what's possible keep expanding at an accelerated pace. One minute you're marveling at a robot that can tidy up your kitchen, the next there's talk of decentralized AI swarms that can simulate entire universes! Where does it end?
Charts that caught my attention
Speaking of mother nature…
1. The Global Biomass of Wild Mammals
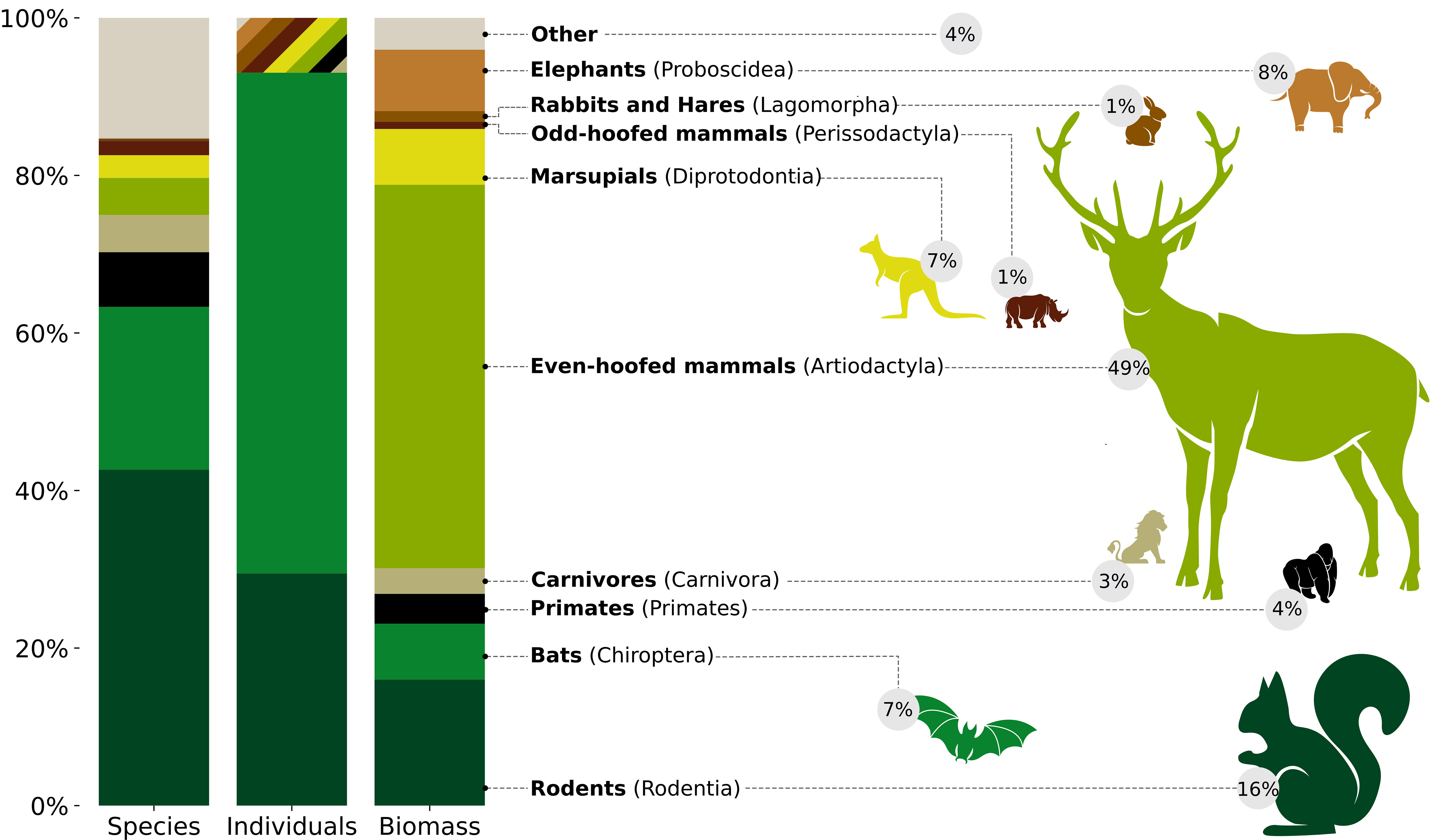
Most of the total mass or biomass of wild land mammals comes from a small number of larger mammal species, those with an individual body weight over 10 kg. In contrast, while comprising >95% of all individuals, the many smaller species under 1 kg in body mass collectively make up only a minor portion of the total mammal biomass. For instance, bats represent about one-fifth of all mammal species and account for roughly two-thirds of all individual mammals, yet they contribute less than one-tenth of the overall biomass of wild land mammals found globally.
In essence, it is the relatively few larger mammalian species that dominate and constitute the bulk of the biomass, even though smaller creatures like bats are vastly more numerous from a species diversity and population standpoint. The distribution of biomass is therefore highly skewed towards the larger mammal species.

The global biomass distribution of the mammalian class, represented by a Voronoi diagram above shows that the global mammalian biomass distribution is dominated by humans and domesticated mammals, including livestock and pets.
2. The Surge in Renewables Capacity

The world achieved a historic milestone in 2023 by adding an unprecedented 510 gigawatts (GW) of new renewable energy capacity, a 50% jump from the previous year. This phenomenal addition is equivalent to the entire power capacity of Germany, France, and Spain combined.