


Google's AI Hustle Paradox, Claude3, Lumiere vs Sora, Superconductivity Scandal, A World Without Farmers #9
and other interesting reads in the past 30 days.

1. Google’s AI Hustle Paradox: From King to Contender
It’s hard being Google this time around.
On one hand, you were expected to deliver excellent results due to your name — Google is practically synonymous with AI. Remember last year's Google I/O where they mentioned "AI" over 100 times during the 2-hour keynote? That’s almost an AI per minute! Talk about trying to hammer home that “we’re the AI company” message. But on the other hand, it feels like they're playing catch-up instead of leading the charge. The past 3 years they’ve been overshadowed by OpenAI’s progress, and 5D chess moves by Satya Nadella. And let's not forget the seemingly endless backlash every time Google drops something new.
But let’s give credit where it’s due. Google’s made some seriously impressive strides with AI lately (as always) and they are clearly pouring all their attention and resources into this, which makes sense — they want that “AI crown” back.
It's wild to think that just 5 years ago, Elon Musk estimated the probability of OpenAI even being remotely relevant to Google was 0%.

Now, Google’s playing catchup, but they’re playing hard. Gemini 1.5 Pro puts them back in the game, barely a week after the launch of 1.0 ultra and its integration with Gemini Advanced (RIP Bard). The highlights for this iteration is about being comparable to 1.0 Ultra while using less compute, and breakthrough in long-context understanding. Google DeepMind is pushing the boundaries and increasing the amount of information that a model can process — up to 1 million tokens (and even 10M in research) from a mere 32,000 tokens in the previous version. For comparison, the GPT-4 Turbo’s context window is “only” 128,000, and 200K tokens for Claude 2.1.

Gemini 1.5 Pro has a photographic memory, or so they say. It can find a tiny piece of information (the "needle") in a massive pile of data (the "haystack") with insane accuracy. We're talking over 99.7% success rate, whether it's digging through text, video, or audio.
And get this: it can keep up this mind-blowing performance even when the haystack gets ridiculously huge. I'm talking 10 million tokens for text (that's like 7 million words!), 2 million tokens for audio (up to a whopping 22 hours!), and 2.8 million tokens for video (a solid 3 hours of footage!). To put things in perspective, Harry Potter books usually contains 75,000-100,000 words or roughly equivalent to ~100,000 tokens. So Gemini 1.5 Pro is able to digest 10x the size of the Harry Potter book at one go. Talk about a huge attention span!

This capability has sparked quite a discussion in the AI community. One hot topic that's got everyone talking is whether Gemini 1.5 Pro could potentially put the final nail in the coffin for RAG (Retrieval-Augmented Generation) — a technique that involves using a separate retrieval system to fetch relevant information from an external knowledge base, which is then fed into a language model to generate a response. But with Gemini 1.5 Pro's ability to find that needle in the haystack, a question arises: why bother with a separate retrieval system when you've got a model that can pinpoint the exact information it needs, even when it's buried deep within a massive pile of data?

It might come down to the cost.
When we take a closer look at the cost-per-call, RAG paired with Gemini 1.0 Pro seems like a pretty sweet deal. At just roughly $0.005 per call (1/100th of Gemini 1.5 Pro), it’s a budget-friendly option that could work for most cases, especially when you need to find specific information and back it up with evidence. However, since RAG rely on retriever, it may struggle with more complex questions that require deeper reasoning or connecting information across multiple retrieved passages. This is a notable leap made by Google and made me wonder about the underlying architecture.
In the technical report, the Gemini Team mentions that they are using Mixture of Experts (MoE), which I also briefly cover in the previous post. MoE architectures have become the bread and butter of most modern Large Language Models (LLMs) — we saw it with Mistral, people said it’s used on GPT-4 too, and now we’ve seen it on Gemini 1.5 Pro. MoEs have enabled the scaling of language models to billions and even trillions of parameters by inducing sparse activations, which is just a fancy way of saying that these models can work faster and more efficiently by distributing the workload.
The benefits of MoE extend beyond LLMs. A recent paper demonstrates that incorporating MoE modules, particularly Soft MoEs into value-based reinforcement learning (RL) network such as DQN and Rainbow, leads to improved performance and optimization stability. The study shows that the performance gains aren’t just because MoEs make the computation more efficient, but also from the structured sparsity induced by multiple experts and the stabilizing effect on optimization dynamics (a.k.a work smarter, not only harder).
But.. just when you thought Google's Gemini 1.5 Pro was the talk of the town, some new models keep coming and suddenly (it’s more than a year already) GPT-4 has four competitors aside from Gemini:
Mistral Large (Released on February 26th). The so called Au Large is Mistral’s “flagship” model, which was claimed to outperforme Anthropic’s Claude 2, Google’s Gemini Pro, and Meta’s largest Llama 2 model on the MMLU benchmark. But unfortunately yet to beat the OG GPT-4. Alongside the release, Mistral also unveiled an AI chatbot called ‘Le Chat’ and of course, multi-year partnership with Microsoft.

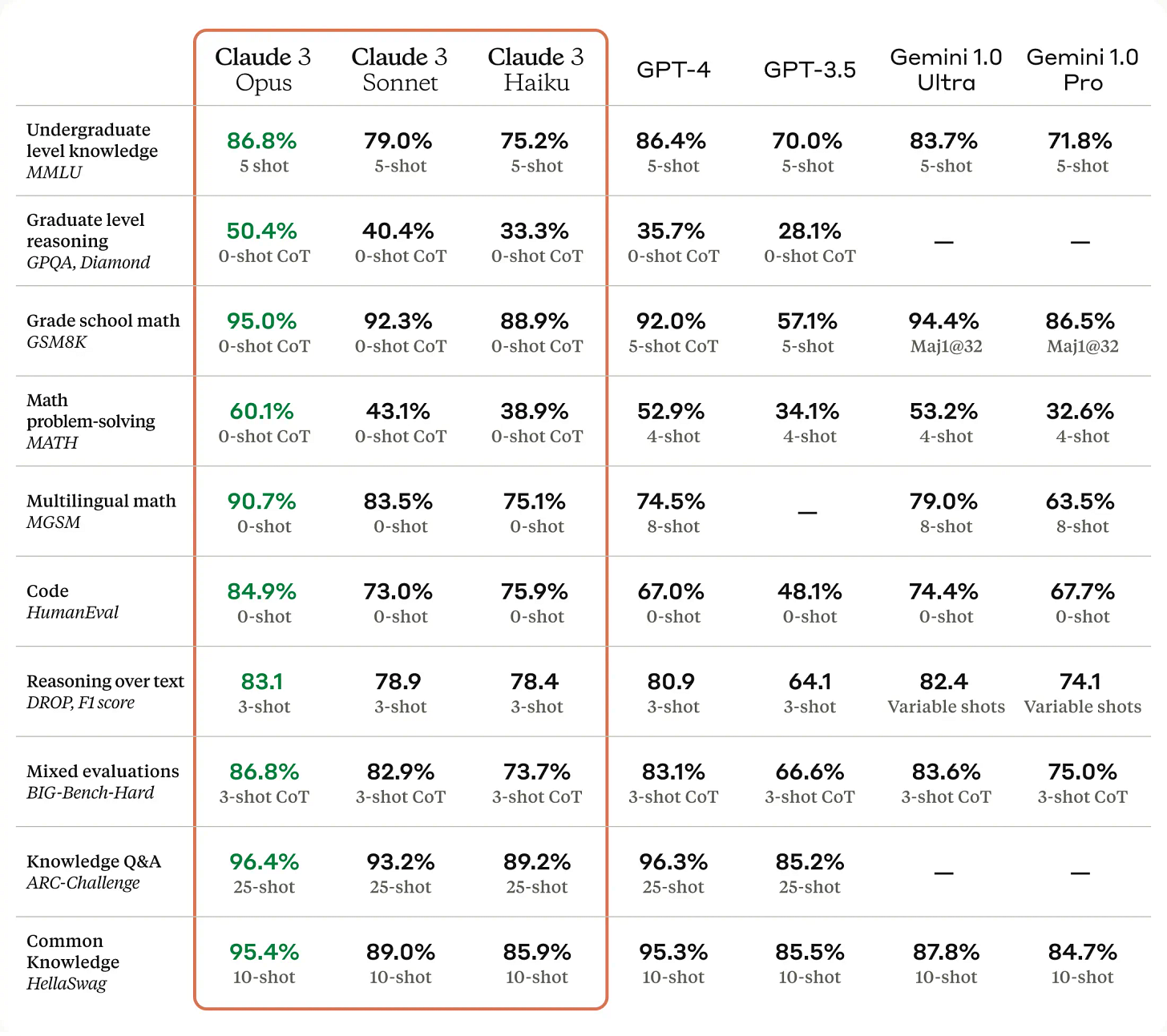
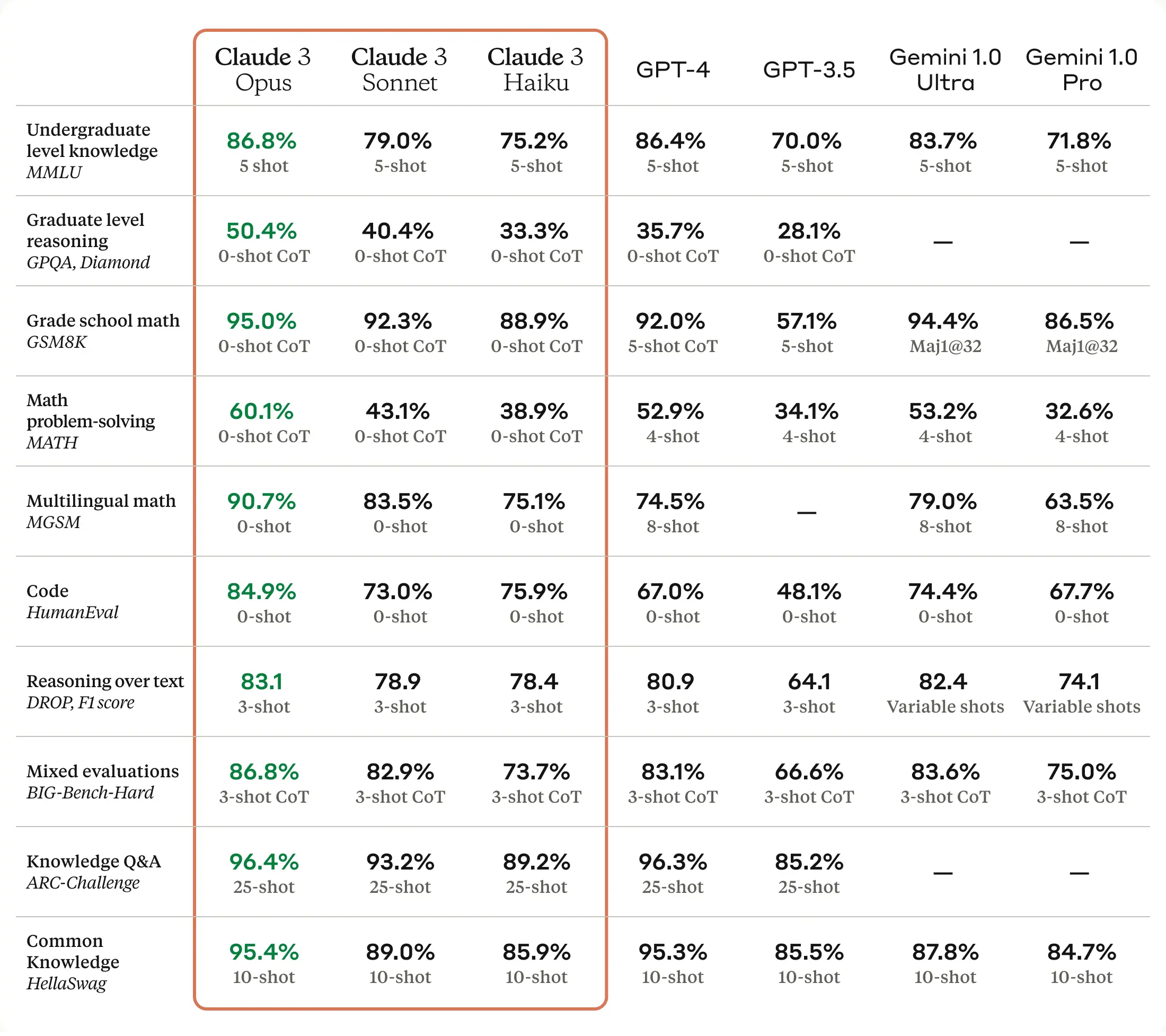
Comparison of GPT-4, Mistral Large (pre-trained), Claude 2, Gemini Pro 1.0, GPT 3.5 and LLaMA 2 70B on MMLU (Measuring massive multitask language understanding). Source Mistral. Claude 3 Opus (Released on March 4th). This model is just a few days old but quickly gained recognition. The Claude 3 family, especially Opus, has been praised by many, dubbed as the first model to truly challenge GPT-4’s dominance.
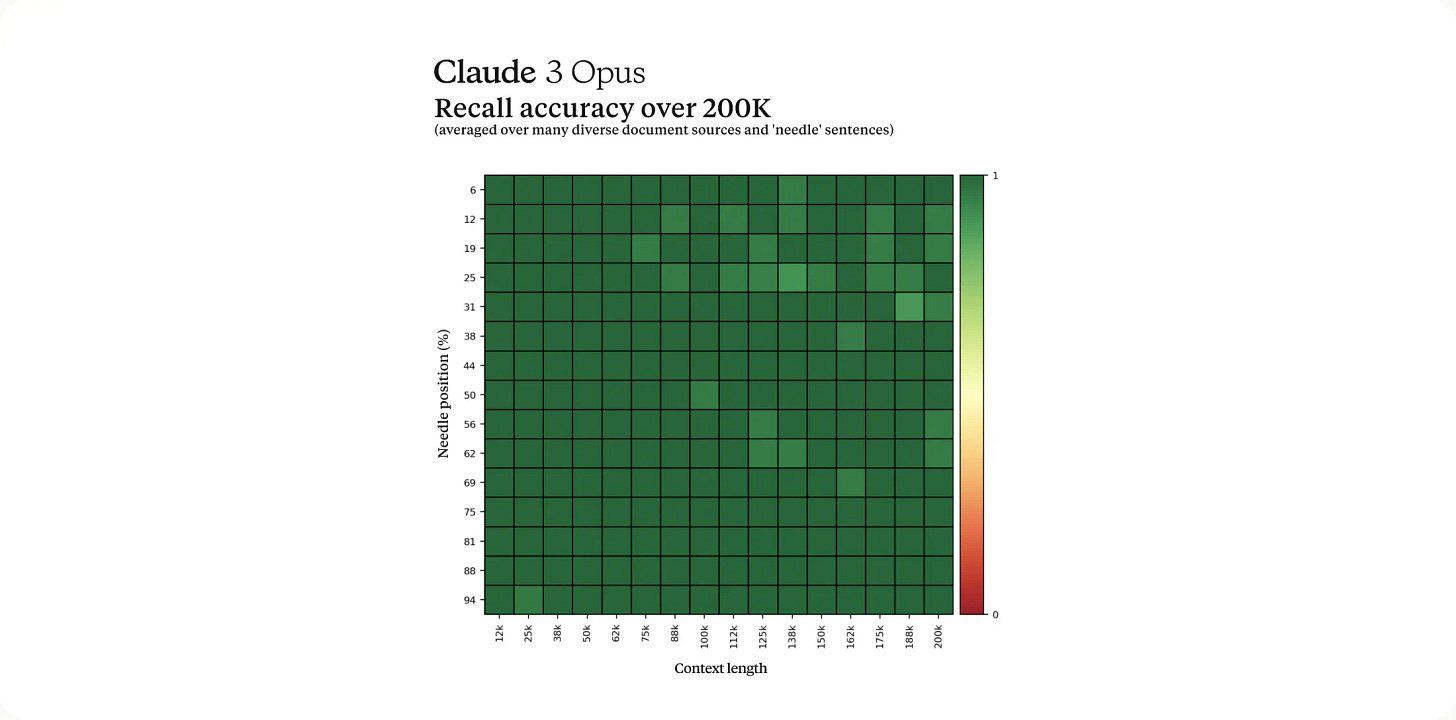
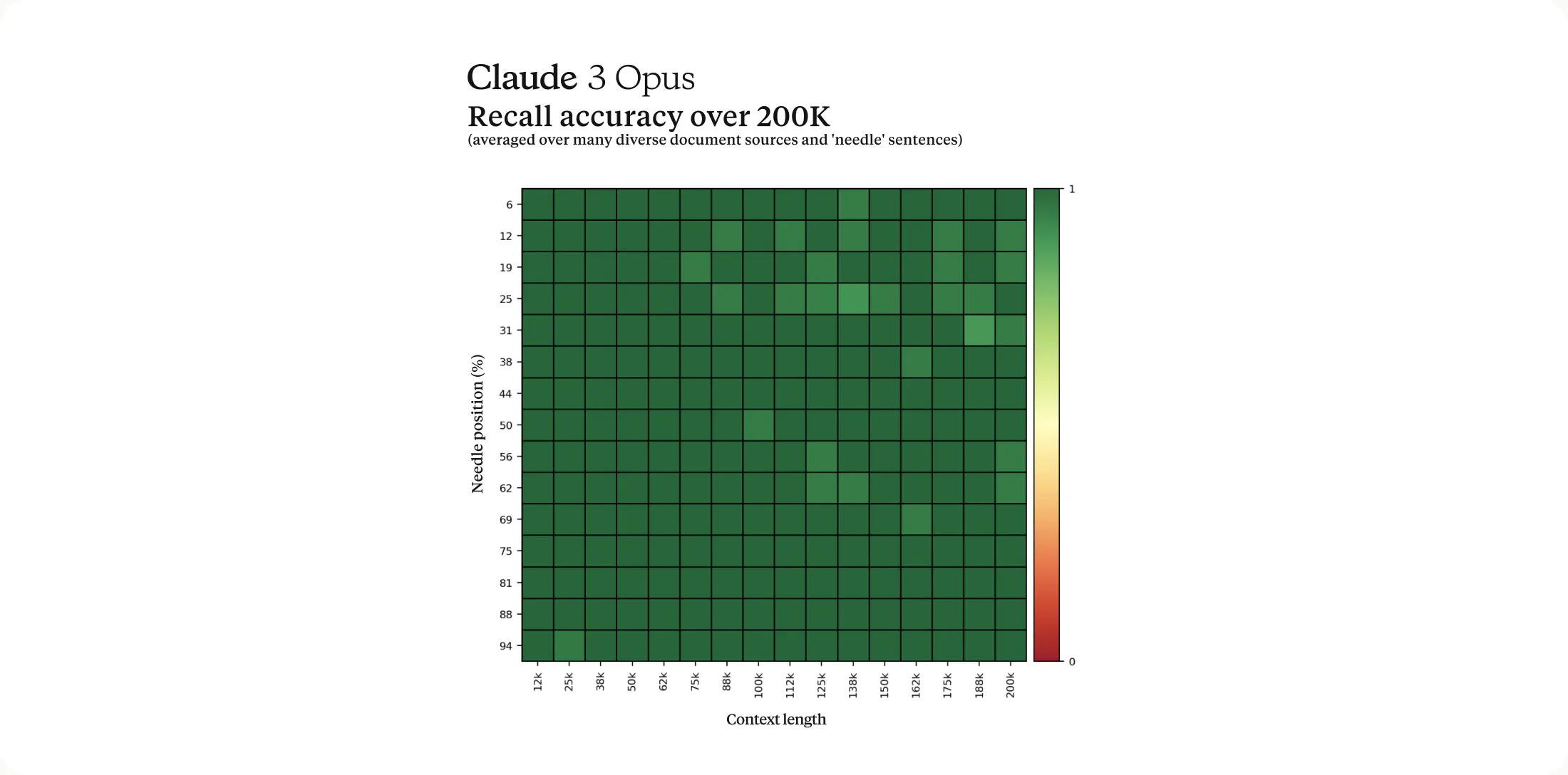
Not to mention that it has also near-perfect recall as Gemini 1.5 Pro, albeit with smaller window (200K).
I’ve been switching from ChatGPT/GPT-4 to Gemini in the past couple of months for most of my cases except coding. I’ve tried using Opus to assist me in coding and wow, it works really well. I’ve also tried to use it for other complex things including analysing images and while I still love the way Gemini structures the answers and their overall UX, Opus’s answers are much better in many ways. The only thing that makes me miss GPT-4 is its image generation ability, because neither Claude and Gemini can do that. Well… technically Gemini can do that but it was… messed up. Here’s my first experiment with Opus. I ask Opus to explain Mixture of Experts using manim, a mathematical animation library in Python (no edit).
Inflection-2.5 (Released on March 7th). To be frank, I haven’t been really paying attention to what Inflection has been doing up to this point, but I think we should be talking about them more — I mean, 6 billion messages and 6 million users is huge, and clearly they are onto something. They just released a near GPT-4 class model, and what really intrigued me was their vision that feels very different from the others. Rather than trying to build another assistant, through Pi, they design the AI to be your best friend instead.


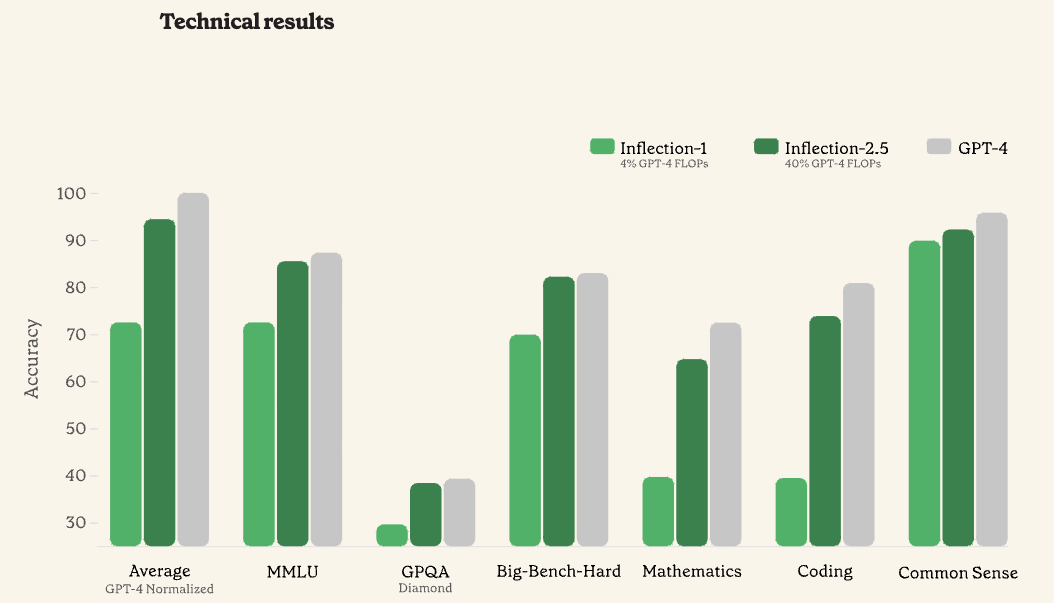
However, as impressive as these language models are, the future of AI i think lies in multimodality in which the system can process and generate multiple types of data, such as text, images, audio, and video, allowing for broader use cases, more comprehensive understanding of the world, and seamless interactions between human and machines. This post is a great primer for this very topic.
2. Stealing the spotlight: OpenAI Sora
Speaking about multimodality. To this date, there have been some players in the video generation models space like Pika and Runway. And of course, Google is no stranger in the field as well. They have developed several video generation models, including Phenaki, Imagen Video, and VideoPoet which was unveiled a couple months ago. But they didn’t stop there. They recently released Lumiere, which builds upon their previous work.

Through Phenaki, Google confirmed the effectiveness of techniques like frozen text encoder conditioning and classifier-free guidance for video generation where they can demonstrate qualitative controllability, such as 3D object understanding, text animation generation, and artistic style generation. Google then introduce Imagen Video, which scaled up to generate high-definition 1280x768 videos at 24 frames per second. With Lumiere, unlike previous models that use temporal super-resolution, Google introduces a Space-Time U-Net architecture that generates the entire temporal duration of the video at once. This way, Lumiere can capture temporal coherence and motion dynamics.
But yet again, in a continuous game of one-upmanship, OpenAI hits back with Sora. In their technical report, “Video generation models as world simulators”, OpenAI is painting a vision of building general purpose simulators of the physical world.
Sora is an end-to-end, diffusion transformer model that takes text or image as input and spits out video pixels directly. That's right, no separate components or complex pipelines. But here's the kicker: Sora doesn't just generate videos; it seems like it learned a physics engine implicitly in its neural parameters through gradient descent and massive amounts of video data. It's a learnable simulator, a "world model" that can generate somewhat “realistic” videos based on textual descriptions, if you will.
However, before we all start imagining for the next Hollywood blockbuster fully directed by an AI, it's worth noting that Sora isn't perfect. Despite its impressive ability to generate convincingly “realistic” videos. It seems to struggle with projective geometry — Sora can't quite grasp the nuances of perspective and spatial relationships and most probably defy the laws of physics.

Other interesting thing I learned is that like many other models, Sora seems to scale well with the amount compute given. As training compute increases, the sample quality improves (from top to bottom: base compute, 4x compute, 32x compute):
Now I understand why Sam need that $7 trilllion: mo’ money, mo’ compute.

In the core essence, Sora is a diffusion transformer with flexible sampling dimensions as the backbone, with 1) a time-space compressor mapping the video into latent space, 2) a ViT processing tokenized latent patches, and 3) a CLIP-like conditioning mechanism.

All in all, Sora pushes the boundaries with longer high-quality videos (1 minute), strong instruction-following capabilities, and embracing the diversity of resolution (1920x1080p videos to vertical 1080x1920p) and everything in between. While Sora's ability to generate longer high-quality videos and its strong instruction-following capabilities suggest it may be more advanced, Lumiere's architectural innovations and focus on realistic motion dynamics also represent significant progress.

Ultimately, the choice of which model is "better" may depend on the specific use case, desired video length, and the importance of factors such as motion realism, stylization, and adherence to instructions. As both companies continue to push the boundaries of video generation, it's likely that we will see further improvements and innovations in this rapidly evolving field.
Charts that caught my attention
1. EVs require a lot of energy to produce. Are they still a greener choice than gas-powered cars in the long run?
And ultimately, does the energy cost of building an electric vehicle negate the benefits of cleaner operation compared to gas-powered cars?

2. Climate Finance Breakdown: Asia accounts for a quarter of the world’s sustainable debt issuance, which includes green bonds
Asia contributed about two-thirds of global growth last year, and will again in 2024. However, the region’s significant dependence on burning coal for energy means that it contributes more than half of harmful global greenhouse gas emissions. Asia has an opportunity to be a leader in the battle against climate change by serving as a model for how countries and regions can simultaneously achieve robust economic development while minimizing environmental impact and transitioning to greener practices.

Other interesting reads
Superconductivity scandal: the inside story of deception in a rising star’s physics lab [Nature]
Why does nature always follow a bell curve? [Ethan Siegel]
Why Japanese cities are such nice places to live [Noah Smith]
Vision-Language Foundational Models [Awais Rauf]
[Not so much interesting, but concerning] → Boeing whistleblower who raised safety concern found dead [Bloomberg]
A World Without Farmers? The Lewis Path Revisited [Bruno Dorin, et al]