


Some interesting things to start the week #5
Small Language Models, Data exhaustion, Prompt engineering, LLMs hallucinations, how they can help make new scientific discoveries and whether their emergent capabilities are just a mirage.


I thought December was going to be a slow down month for everybody, but boy.. this post is gonna be so packed. People in the space just can’t take it slow.
In today’s edition:
💾 Small Language Models, and the world is running out of data
👑 The new king of MMLU benchmark
🤖 Can we prompt our way towards AGI?
🐞 LLM hallucination; a bug or a feature?
⏳ Could the emergent properties be just a mirage?
1. Let’s start small, and why is it the next big thing instead
Compact, yet powerful models are always welcome. In fact, very much needed. The ability to train compact models with cutting-edge capabilities would democratize advanced AI, enabling a broader range of individuals and organizations to study and deploy them, instead of being an exclusive domain of a few with vast computational resources — overall better for the pocket and environment alike.
Previously we talked about Mixtral - Mixture of Experts and Mamba - Selective State Space Models, where they punching above their weight compared to models 10-25 times larger.
Phi-1 and Phi-1.5 are among my favourites, and recently Microsoft just released a new generation of Phi family: Phi-2, a 2.7 billion-parameter language model that demonstrates outstanding reasoning and language understanding capabilities, showcasing state-of-the-art performance among base language models with less than 13 billion parameters. On complex benchmarks Phi-2 matches or outperforms models up to 25x larger, thanks to new innovations in model scaling and training data curation.

What I like about the Phi models are that their focuses on a different axis: the quality of the data. Common wisdom in machine learning has recognized the importance of data quality, but the Phi models take this to a new level. By meticulously selecting and filtering their training data, they achieve remarkable results with significantly smaller model sizes and training costs. This suggests that a shift towards focusing on data quality could have a profound impact on the future of AI development.
2. We are running out of data
Speaking of the importance of data, Chinchilla’s wild implications argued that training data would soon become a bottleneck for scaling large language models, and the bad news is we might run out of it.
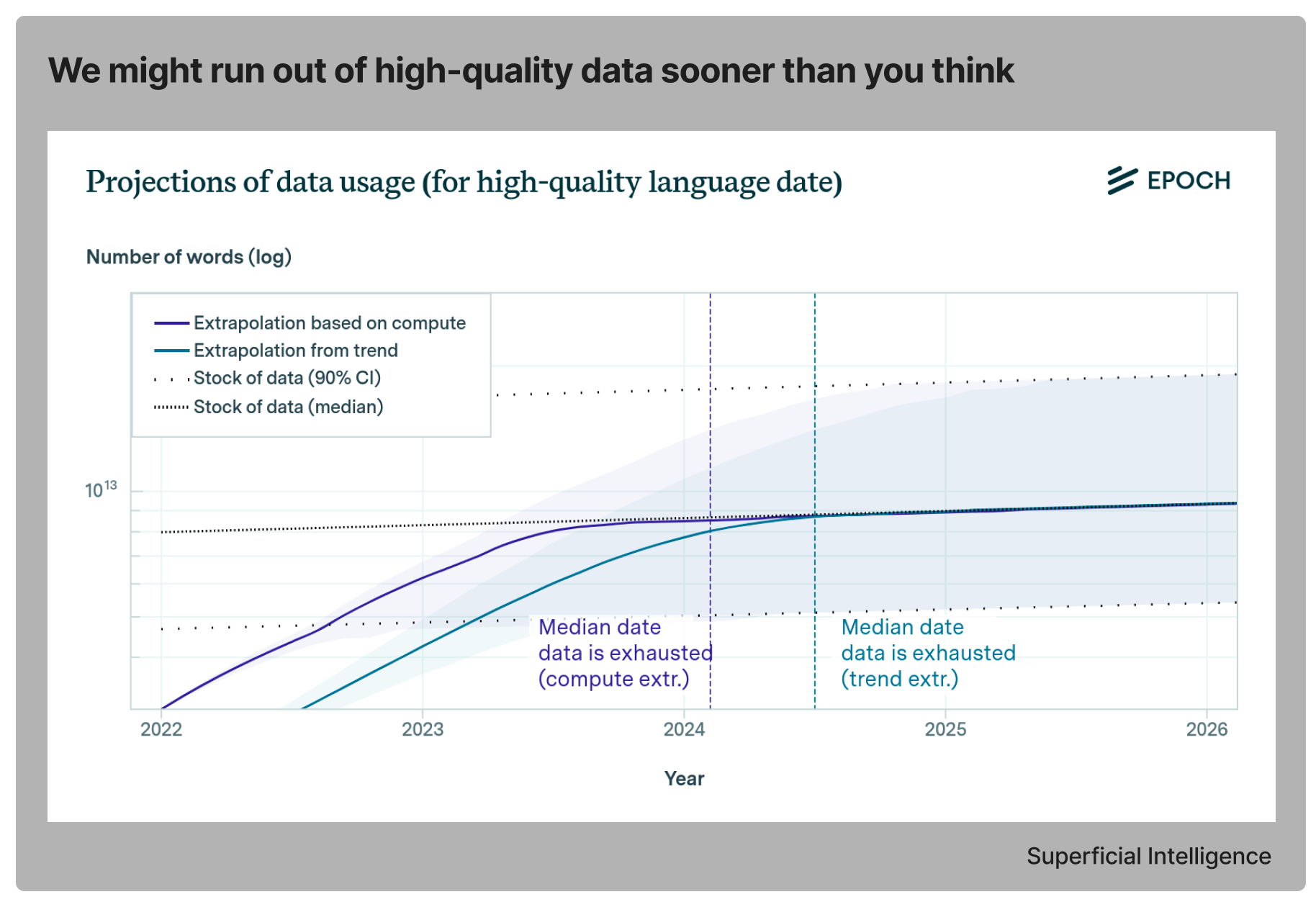
Humans, though, we really are a creative species. Folks at DeepMind just released a paper - Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models. Model-generated synthetic data emerges as a promising alternative to human-generated data, offering scalability and cost-effectiveness, as long as we can ensure its quality. The paper explores a setting where an external, scalar feedback signal based on expectation-maximization serves as a quality indicator for each generated sample. Overall, the findings suggest self-training with feedback can substantially reduce dependence on human-generated data, and not only that, it also scales favorably with model size and significantly surpasses fine-tuning only on human data.
3. The king is back
Last week, Google’s Gemini Ultra dethroned GPT-4 and claimed supremacy especially in the MMLU benchmark. But that didn’t last long. In just a couple of days, the team at Microsoft has shown that if Gemini can beat GPT-4 by practically ‘inventing’ a new technique called uncertainty-routed Chain-of-thought — where model produces k chain-of-thought samples, selects the majority vote if the model is confident above a threshold, and otherwise defers to the greedy sample choice.
Well, I can do that too! say Microsoft.
The Microsoft team steers GPT-4 with a modified version of Medprompt, called Medprompt+, to achieve the highest score ever achieved on the complete MMLU, and voila… SOTA frontier model has been reborn, yet again.
 achieved 78.4% accuracy, Claude 2 (5-shot CoT) achieved 78.5% accuracy, Inflection-2 (5-shot) achieved 79.6% accuracy, Google Pro (CoT@8) achieved 79.13% accuracy, Gemini Ultra (CoT@32) achieved 90.04% accuracy, GPT-4-1106 (5-Shot) achieved 86.4% accuracy, GPT-4-1106 (Medprompt @ 5) achieved 89.1% accuracy, GPT-4-1106 (Medprompt @ 20) achieved 89.56% accuracy, and GPT-4-1106 (Medprompt @ 31) achieved 90.10% accuracy.")
MMLU(opens in new tab) (Measuring Massive Multitask Language Understanding) challenge was established as a test of general knowledge and reasoning powers of large language models. The complete MMLU benchmark contains tens of thousands of challenge problems of different forms across 57 areas from basic mathematics to United States history, law, computer science, engineering, medicine, and more.
But I think the point is not who’s back on top, but a valuable insight regarding prompt engineering and its correlation with performances — which we have also addressed in the previous roundup.
While systematic prompt engineering can yield maximal performance, what’s more interesting to be explored is actually out-of-the-box performance of the foundation models with only simple prompts, as demonstrated in the below table. Before diving into more sophisticated and expensive techniques, employing simple prompts to establish baseline can be very useful.

This actually begs a question… can we prompt our way towards AGI?
4. Can we prompt our way to an AGI?

OpenAI just dropped their Prompt Engineering guides, on top of already comprehensive Microsoft’s Promptbase. Signifying the importance of prompt engineering — also known as In-Context Prompting, which refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights.
However, as models grow more capable, can careful prompting unlock abilities approaching human cognition? Or are architectural constraints an obstacle no prompt can currently overcome?
Some folks on X (previously twitter) believe that better prompting could be a way to reach AGI, or at least believe that it leads somewhere around that, except of course Yann LeCun, and some others as well.

LLMs are bound to hallucinate due to its underlying architecture and they way they are trained — next-token prediction. Making them sensitive to contextual information. As Andrej Karpathy said, hallucination is all LLMs do. They are dream machines.
We direct their dreams with prompts. The prompts start the dream, and based on the LLM's hazy recollection of its training documents, most of the time the result goes someplace useful. It's only when the dreams go into deemed factually incorrect territory that we label it a "hallucination". It looks like a bug, but it's just the LLM doing what it always does. - Andrej Karpathy
In general, Language models and search engines represent two extremes - unconstrained imagination versus bounded accuracy. An LLM is 100% dreaming and has the hallucination problem. A search engine is 0% dreaming and has the creativity problem. Something we need to find the function to maximize of. The ideal AI system should balance open imagination with focused accuracy.
Overall, prompting is a promising tool for pushing the boundaries of LLMs, but it's likely just one piece of the puzzle in the quest for AGI. Combining prompting with other research directions, such as reinforcement learning, neuro-inspired models, and better understanding of human intelligence, could be crucial for making significant progress towards this ambitious goal.
Follow-up read: System 2 Attention
5. LLMs help us make scientific discoveries
Here’s a question: could LLMs discover entirely new knowledge?
If we think about it, since hallucinations are a feature, not a bug - we can get LLMs to dream up possible solutions to complex problems.

That’s what the Google DeepMind team just did. In “Mathematical discoveries from program search with large language models”, they introduce FunSearch:
Key points:
FunSearch is a new method that uses large language models (LLMs) to discover new solutions in mathematics and computer science.
It works by pairing an LLM with an automated evaluator to avoid hallucinations and generate better solutions over time. By iterating back-and-forth between these two components, initial solutions “evolve” into new knowledge.
FunSearch has made significant breakthroughs in two areas:
Cap set problem: Discovered the largest known cap sets in specific settings, surpassing state-of-the-art methods. The problem consists of finding the largest set of points (called a cap set) in a high-dimensional grid, where no three points lie on a line. This problem is important because it serves as a model for other problems in extremal combinatorics - the study of how large or small a collection of numbers, graphs or other objects could be.
Bin-packing problem: Found new algorithms that outperform existing heuristics, requiring fewer bins to pack items.
The benefits of FunSearch:
Discoveries: Makes new discoveries beyond established results.
Interpretability: Generates programs that explain how solutions were found, providing deeper insights.
Practical applications: Solutions can be readily implemented in real-world problems.
FunSearch proves that, by controlling LLMs' hallucinations, we can leverage their incredible abilities to not only make groundbreaking discoveries in math, but also find practical solutions to important problems in the real world, like packing things efficiently or optimizing computer tasks.
6. Emergent properties might be just a mirage
Or is it a shimmery glimpse of the future?

The best paper award in NeurIPs 2023 went to a paper that argues that the emergent abilities of LLMs could be a mirage!
Emergence is when quantitative changes in a system result in qualitative changes in behavior. - Jason Wei et al
Definition of Emergence: In the context of LLMs, "emergence" typically refers to the phenomenon where a system exhibits abilities or behaviors that were not explicitly programmed or anticipated by its creators.
Wei et al (2022) argues that LLMs demonstrate emergent capabilities - as models scale in size, they exhibit novel capabilities not present in smaller models. They analyze several tasks where larger LLMs outperform smaller ones, including reasoning about abstract concepts, following complex instructions, and generating different creative text formats. These abilities are said to be sharp (transition instantly from not present to present) and unpredictable.
However, Schaeffer et al. (2023) took a more skeptical view, arguing that the apparent emergence of new abilities in LLMs can be explained by factors other than pure scale, such as improved training data or specific architectural choices. They call for a more nuanced understanding of what constitutes emergence and how it should be measured. They argue that these apparent emergences are instead caused by:
Metric choice: Non-linear or discontinuous metrics can distort performance curves, making improvements appear sudden and unpredictable.
Limited test data: Smaller models may be unfairly handicapped by insufficient test data, further exaggerating the performance gap

Source: https://arxiv.org/abs/2304.15004

As research progresses, we will likely gain a deeper understanding of the true nature of LLMs' capabilities and their potential implications for the future of AI.
Perhaps the most interesting aspect of LLMs isn't just their current capabilities, but the questions they raise about the nature of intelligence and the potential for human-machine collaboration.
Other interesting things to read this week:
Quantum-computing approach uses single molecules as qubits for first time (Nature)
MrBeast’s Analytics Platform ViewStats is Out in Beta (TechCrunch)
Is it possible that gravity isn’t quantum? by Ethan Siegel
Scientists drilled through 500 metres of Greenland’s ice — here’s what they found at the bottom