


LLM-Powered Autonomous Agents, Compound Systems, Multi-trillion Parameters Training, Gigawatt Clusters #11
And how we'll reach a 1 trillion transistors GPU

For me, the pace of AI development became too rapid to keep up with these days. So, in the past couple of months, I decided to take a step back and do what any reasonable person would do: go back to basics.
Then I brushed up on my fundamentals, hoping that by solidifying them, it would help me better understand these accelerated developments. I found (and read) some great books along the way:
Sebastian Raschka's "Build a Large Language Model (From Scratch)"
"Mathematics for Machine Learning" by Faisal, Ong, and Deisenroth
Did I manage to finish them all, cover to cover? Most certainly not. Instead, I also picked up Rust programming and somehow drifted into biology and genomics territory. Suffice to say, I learned more than I initially planned while simultaneously less than I should.
Anyway, let’s get to the main talking point.
1. Building AI brick by brick: From Model-centric to System-centric
In the early days of Large Language Models (LLMs) — I’m referring to 20-ish months ago when GPT-4 was first launched — their potential seemed limitless, the focus was on the models themselves as the key ingredient to unlocking AI’s power. However, it seems like the focus is rapidly changing. While training will continue to be a key differentiator between the best AIs and the rest, State-of-the-art AI results are increasingly achieved by systems with multiple components, not just monolithic models. The folks at Berkeley AI Research call these “Compound Systems”, which basically means that it’s not LLMs models alone now, but rather a carefully engineered, multi-components and multi-layered systems which actually offers lots of advantages.
We've seen the success of compound systems in examples like: AlphaCode 2, AlphaGeometry, Gemini and OpenAI Plus. However, we know that there’s no free lunch.. these types of systems pose several challenges as well, from design (choosing and configuring components), optimization (co-optimizing components for best performance), all the way to the operation phase (monitoring, data management, and security).
The Rise of Agentic AI
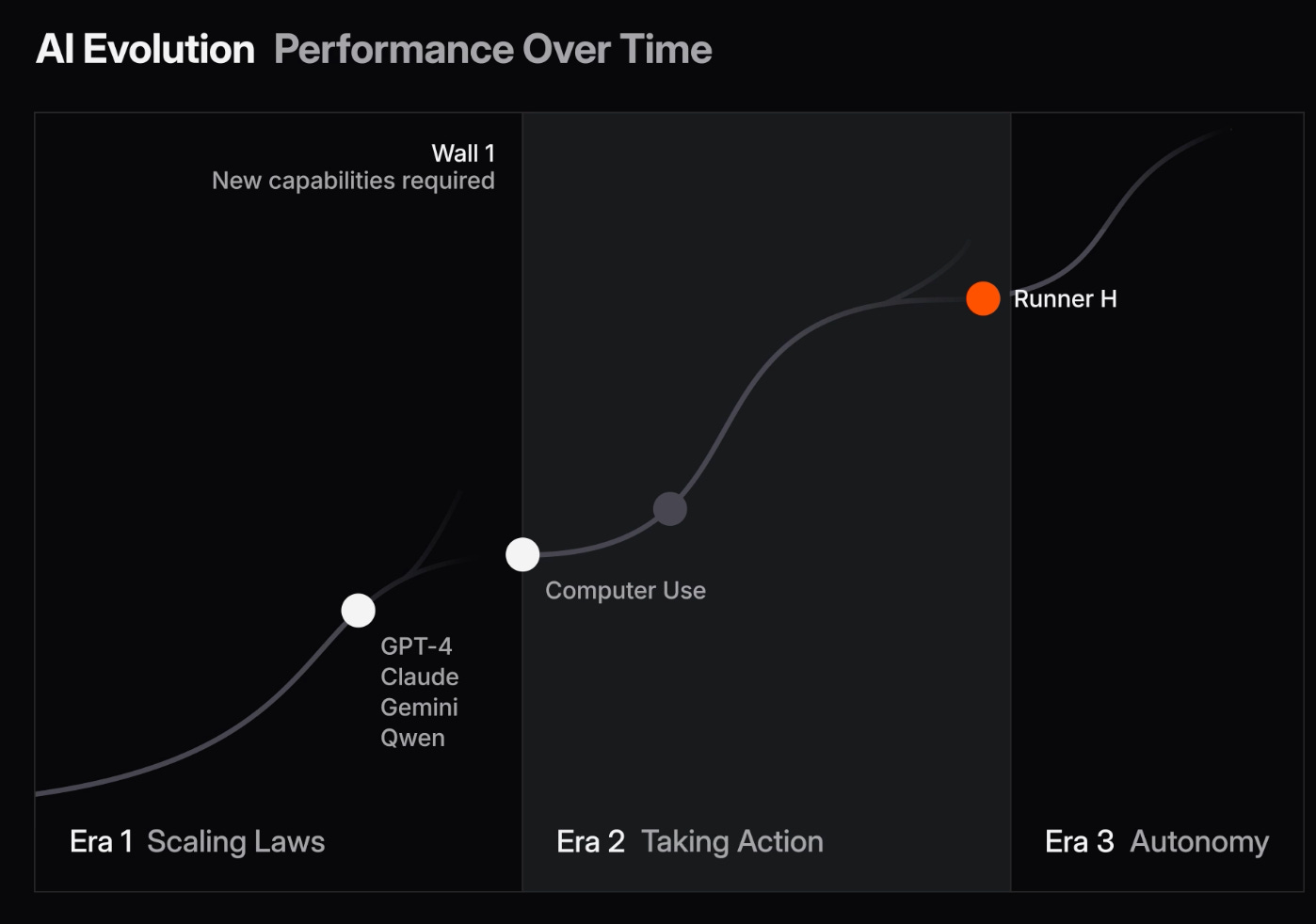
This shift towards compound systems naturally leads us to the recent development: LLM-powered autonomous agent. Moreover, many have been wondering what’s next after the chatbot. Recently, there’s a camp that feels that we might have hit a wall (See Figure 0).
I've actually been meaning to write about this particular topic since March, but somehow got sidetracked. Now it's caught my attention again, mainly because Anthropic just released their new Computer Use capability. And as expected, the Twitter-verse (haven't gotten used to saying 'X' till now) has filled with reactions.
And recently a company called H Company launched their studio platform to create production-ready automations. Currently focus one the web but they planned to extend beyond the web going forward, which is really cool.
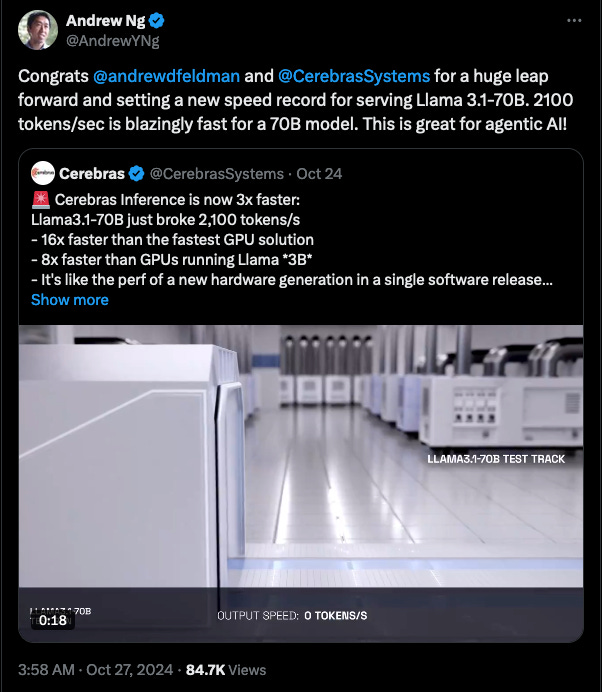
Adding to the context: Cerebras just shattered their own records; tripling their inference speed from 650 t/s to 2100 t/s which prompted Andrew Ng to tweet this:
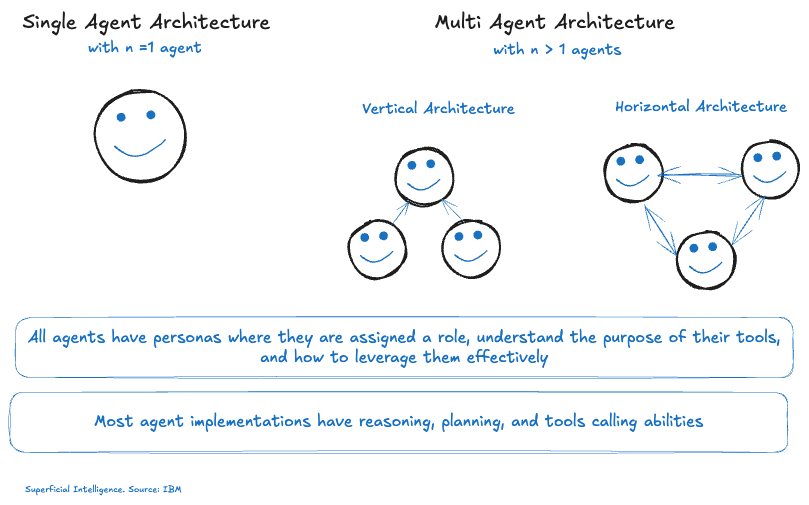
But why does this matter? and what exactly IS Agentic AI?
TLDR; AI agents are artificial entities that sense their environment, make decisions, and take actions.
Agentic AI is all about AI that doesn't just answer our questions or write poems, but actually does things in the real world, on our behalf. These systems act independently, continuously interacting with their environment, analyzes their situational context and selects behaviors that will move them toward accomplishing their objectives; This makes them capable of handling much more complex tasks.

The concept of agents in AI dates back to the mid-20th century, when researchers envisioned creating intelligent artificial entities1. These early agents, however, were limited in scope, and focused on specific tasks like symbolic reasoning or game playing like mastering Chess or Go23.
Moreover, previous research have placed more emphasis on the design of algorithms and training methods, rather than improving the model’s core abilities like knowledge memorization, long-term planning, effective generalization, and efficient interaction4.
But things are changing. Recently, many researchers have leveraged LLMs as the foundation to build AI agents (as the brain, to be specific) and the results are exciting. This is where speed becomes crucial. Faster inference means these LLMs-based agents systems can think, learn, and act more quickly; Paired with the ability to use tools, plugins, and function calling, agents are empowered to do more general-purpose work.
Imagine the possibilities: book me a flight to Bali next week, buy me a ticket to the concert, build me an app to track my reading progress, write and article about Agentic AI…

Now, some might argue that Agentic AI is just another corporate-cooked word, invented to attract more funding. And they might have a point. After all, we've seen our fair share of AI buzzwords come and go, evaporate as quickly as they emerged. But I think we might be onto something here, if we can tackle the challenges ahead.

Agentic AI and function calling are close, but there are some key distinctions. Agentic AI is like giving AI a sense of purpose. It's not just about following instructions (like with function calling), it's about setting goals and figuring out how to achieve them. Function calling gives LLMs the ability to interact with the world (the "hands"), but Agentic AI provides the decision-making power (the "brain"). So, while both concepts are intertwined, they represent different levels of AI development.
And that's where things get really interesting, especially when you start connecting these agents together. Imagine a whole network of agents working together, each with its own goals and abilities, collaborating to solve complex problems. (OR, cascading collective failures).
Compounding Failures
Here’s a critical challenge: as we move towards deploying LLMs in collaborative, multi-agent systems, a big challenge emerges: how can these diverse and computationally demanding models communicate effectively at scale? This challenge was referred as the "Agent Communication Trilemma" in a recent paper by Marro et al.,.5 in which they also propose an interesting hypothesis: “A network of heterogeneous LLMs can automate various complex tasks with nearly no human supervision via specialised and efficient protocols.”
Even in a single agent setting, the accuracy of an agent is still an open problem. As you might have seen from Figure 2 above, in which Open AI proposes levels of AI, agent belongs to Level 3. Meanwhile, we haven’t really solved reasoning ability of an AI (Level 2).
Take a look at the table below, which demonstrates the exponential error compounding effect. As the number steps increases, even small errors in the previous step accumulate rapidly, significantly impacting the overall accuracy. To achieve 95.12% accuracy at 50 steps, agents need to be 99.9% accurate at the single-step level.

To give you an example of how tricky it is, let’s dissect one component of agents: the Planning/Reasoning component (See Figure 4).
A complicated task usually involves many steps and an agent needs to know what they are and plan ahead. To do this, they have to decompose the task at hand.
One standard technique for enhancing model performance on complex task is the Chain of Thoughts (CoT; Wei et all. 2022)6 in which the model is encouraged to “think step by step” to utilize more computation and break the task into smaller and simpler steps. A similar process is being used in the latest OpenAI’s Strawberry model (o1), where the models prioritize thinking before responding. I think going forward, the scaling laws would also apply to test-time compute.
 on the x-axis. The dots indicate increasing accuracy with more compute time.")
An extension to CoT is Tree of Thoughts (Yao et al. 2023)7. Instead of just thinking in a straight line, it explores many different ideas at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure of possible solutions. To find the best solution, it can either search all the branches at the same level first a.k.a BFS (breadth-first search) or go deep down one branch before trying others i.e DFS (depth-first search). A classifier or a majority vote then helps to evaluate and decide which thought is the best.
Another approach to tackle planning is LLM+P (Liu et al. 2023)8 ; mostly used in robotics and it relies on an external planner by utilizing the Planning Domain Definition Language (PDDL) and works as follow: 1) The LLM translates the problem into a language that the external planner understands 2) The external planner creates a plan based on its existing knowledge 3) The LLM translates the plan back into natural language instructions.
Now, that is only the task decomposition part. When we talk about another part of the agent, like “self-reflection,” it involves many other methods to refine past action decisions and correcting previous mistakes: 1) ReAct (Yao et al. 2023)9, 2) Reflexion (Shinn & Labash 2023)10, 3) Chain of Hindsight (CoH; Liu et al. 2023)11.

With these illustrations, we can get a grasp on how likely accuracy will deviate in each step. This is further complicated by the involvement of multiple modalities: text, image, audio. And when we consider memory, with its different types and stages, as illustrated in Figure 7 above, the complexity increases. Each type of memory plays a role in how an LLM reasons and plans, from working memory to long-term memory.
Although H Runner achieved an exciting accuracy, compared to WebVoyager, AgentE, and Claude’s Computer Use, it’s still in the sub-70% area. We clearly still have a long way to go.

How to improve it even further then? I think the answer still rely on the brain part (that is, LLM). Of course, the other part of the agents obviously have other challenges too, but the uncertainty mostly lies in the LLM’s part: 1) Specifically for long-term planning, LLMs still struggling to adapt their plans when things go wrong 2) LLMs have trouble reliably interacting with external tools due to the unpredictability of natural language.12 13 14 15
The computational demands of running and training complex, interacting AI agents are driving an unprecedented push for more compute power.
2. Multi-trillion Parameters LLMs Training and One Trillion Transistor GPU
While scrolling through LinkedIn, a place where, ironically, there have been few insights compared to other not-so-professional social media, I came across the following charts by Peter Gostev which was really insightful.

This finding might not apply to Gemini/OpenAI/xAI, which pretty much scales their compute, but open-source models seem to focus a lot more on data. However, no one has yet trained a massive multimodal transformer with multi-trillion of parameters on a vast dataset of video, images, audio, and text. Even OpenAI admitted that they only recently started training a new frontier model and instead focused on bringing cheaper models like GPT-4 turbo and GPT-4o. The race is on to see who will be the first to achieve this milestone.
AI is unlike any other that come out of Sillicon Valley in the past. It demands a whole new level of infrastructure: each new model requires a colossal new cluster of compute (funny that the largest compute cluster now is named Colossus). Of course, we have to build giant new power plants, and eventually giant new chip fabs. The investments are mind-boggling, but they are already in motion.
It’s hard to think about the sheer of scale of these. But it’s happening. Zuck bought 350k H100s. Google is building 1GW data centers, so does Amazon which recently bought a 1GW datacenter campus next to a nuclear power plant. Last month, Microsoft and Constellation Energy signed a power deal to help resurrect a unit of the Three Mile Island plant in Pennsylvania, the site of the worst U.S. nuclear accident in 1979. And it’s not only happening in the US. Rumors suggest a 1GW, 1.4M H100-equivalent cluster (~2026-cluster) is being built in Kuwait and Saudi Arabia will build a 1GW AI data center in Oxagon.
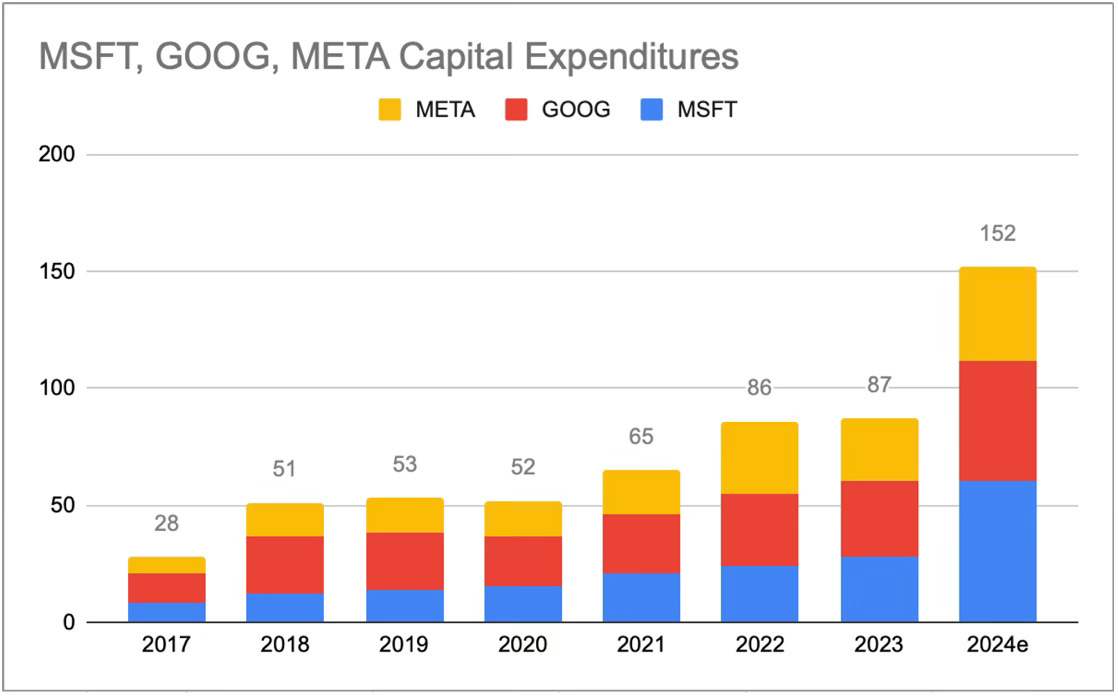
It’s not just Big Techs, but entire nation-states, are pouring money into AI-related capex like never before. Microsoft and Google are projected to exceed $50 billion, with AWS and Meta close behind at over $40 billion, even Tesla is investing more than $10 billion for AI this year. If you think $150+ bio combined already sounds like a huge investment, wait until you see the projected investment by 2030. A $1T per year? not an impossible number.
This is an interesting shift, given these companies used to grow with very little capital invested in the past, but now they have mountains of capital to deploy… who can blame them? And if the Return on Invested Capital (ROIC) is good, then why not? right? Perhaps those $12-$15 Billion depreciation costs are the price they pay to maintain their position; or fuel further growth. Who knows.
Other than compute, one of the biggest constraint on the supply-side will be power. But let’s save that for another time.
Another key factor here is “energy-efficient” computing, and it has something to do with the Chips, although scale-wise, it’s not really a concern. Except that there are shortage of CoWoS (Chip-on-Wafer-on-Substrate) — a cutting-edge packaging technology that allows for tighter integration of different chip components. All in all, global production of AI chips is still a pretty small percent of TSMC-leading-edge production, likely less than 10%. So there’s a lot of room to grow.
For the past 30 years, we owe the AI breakthrough to not only software, algorithms, architecture and other layers, but more importantly, to the cutting-edge semiconductor technology in each phase. From 0.6 and 0.35-micrometer technology powering Deep Blue, to 40-nanometer technology used to conquer the ImageNet, 28-nanometer technology to achieve AlphaGo, and recently, 5-nanometer tech for the first version of ChatGPT.
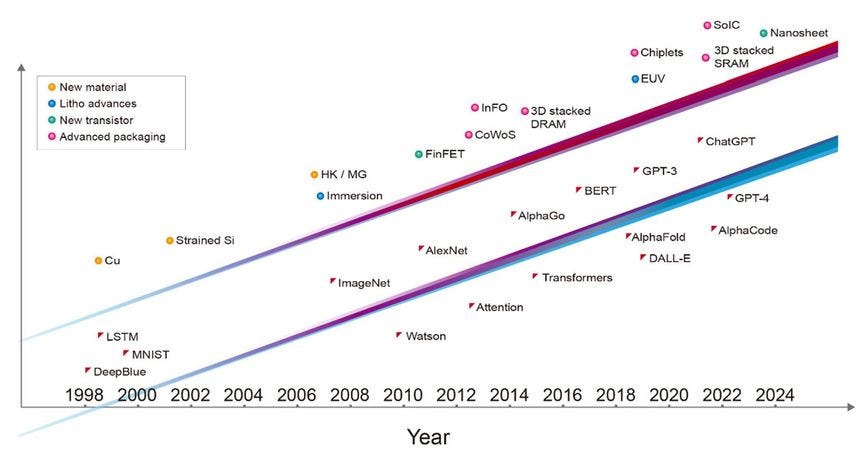
The 100 Billion transistors barrier was just passed a couple of months ago by NVIDIA’s Blackwell GPU but that’s not enough. To keep the AI revolution going at its current pace, the semiconductor industry will need to step up its game. Within the next decade, we'll need GPUs with a trillion transistors—that's 10 times the number in today's typical GPUs.
While packing more transistors onto each chip is important, it's not the only factor in reaching the trillion-transistor milestone. 3D chiplets, the cutting-edge technology of stacking and connecting multiple chips, will be crucial for building the world's first trillion-transistor GPU.
For decades, semiconductor development was all about shrinking transistors in two-dimensional plane. Now, we're entering a new era of possibilities, where GPUs can break free from traditional constraints of 2D scaling. Energy-efficient transistors, innovative architectures, and the synergy between software and hardware will unlock new levels performance and that’s what matters.
Charts that Caught My Attention
1. Almost everybody has uranium.
It's mining it that's difficult.

2. The Latest WayMo California Driverless Rise Stats Are Out
In August 2023: 12,000 for the month. In August 2024: 312,000 for the month.

Other Interesting Reads
Machine of Loving Grace by Dario Amodei (CEO of Anthropic)
The Illustrated AlphaFold by Elana Simon et al (Stanford University)
Magnetic control of tokamak plasmas through deep reinforcement learning by Degrave, J., et al
Theory Is All You Need: AI, Human Cognition, and Causal Reasoning by Fellin et al
Cognition is All You Need -- The Next Layer of AI Above Large Language Models by Spivack et al
How to make peace with the weirdness of quantum mechanics by Ethan Siegel
Novel quantum computing algorithm enhances single-cell analysis
References
Durante, Z. et al. Agent AI: Surveying the Horizons of Multimodal Interaction. Preprint at https://doi.org/10.48550/arXiv.2401.03568 (2024).
Guha, R. V. & Lenat, D. B. Enabling agents to work together. Commun. ACM 37, 126–142 (1994).
Kaelbling, L. P., et al. An architecture for intelligent reactive systems. Reasoning about actions and plans, pages 395–410, 1987.]
Wang, Z., G. Zhang, K. Yang, et al. Interactive natural language processing. CoRR, abs/2305.13246, 2023.
Marro, S. et al. A Scalable Communication Protocol for Networks of Large Language Models. Preprint at https://doi.org/10.48550/arXiv.2410.11905 (2024).
Wei, J. et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Preprint at https://doi.org/10.48550/arXiv.2201.11903 (2023).
Yao, S. et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Preprint at https://doi.org/10.48550/arXiv.2305.10601 (2023).
Liu, B. et al. LLM+P: Empowering Large Language Models with Optimal Planning Proficiency. Preprint at https://doi.org/10.48550/arXiv.2304.11477 (2023).
Yao, S. et al. ReAct: Synergizing Reasoning and Acting in Language Models. Preprint at https://doi.org/10.48550/arXiv.2210.03629 (2023).
Shinn, N. et al. Reflexion: Language Agents with Verbal Reinforcement Learning. Preprint at https://doi.org/10.48550/arXiv.2303.11366 (2023).
Liu, H., Sferrazza, C. & Abbeel, P. Chain of Hindsight Aligns Language Models with Feedback. Preprint at https://doi.org/10.48550/arXiv.2302.02676 (2023).
Wu, W. et al. Mind’s Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models. Preprint at https://doi.org/10.48550/arXiv.2404.03622 (2024).
Sun, J. et al. A Survey of Reasoning with Foundation Models. Preprint at https://doi.org/10.48550/arXiv.2312.11562 (2024).
Li, X. A Review of Prominent Paradigms for LLM-Based Agents: Tool Use (Including RAG), Planning, and Feedback Learning. Preprint at https://doi.org/10.48550/arXiv.2406.05804 (2024).
Masterman, T., Besen, S., Sawtell, M. & Chao, A. The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey. Preprint at https://doi.org/10.48550/arXiv.2404.11584 (2024).