


Quantum Chip and World Simulation #12
Making sense of the future of computing, plus updates on frontier models & techniques: Gemini 2.0, Phi-4, OpenAI o3, Sora, Veo2, Genesis, and Byte Latent Transformers.

0. Quick Updates
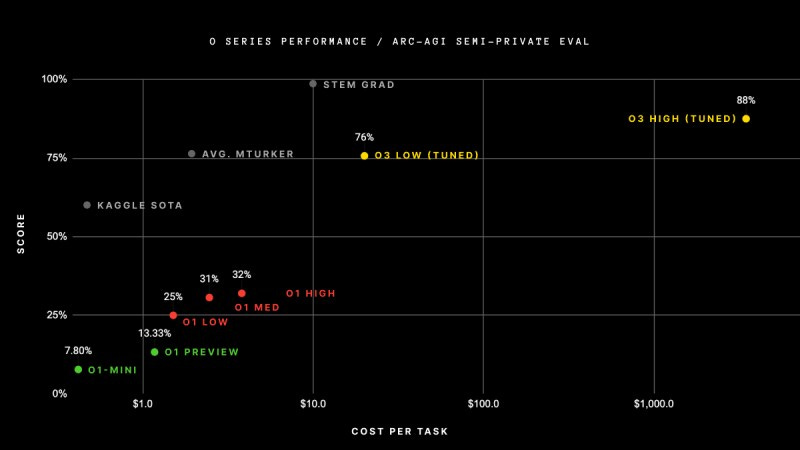
It's December, and the tech world is anything but relaxed. Exhibit A: Google just announced Willow, their advancement in quantum computing (which we’ll explore in this piece). At almost the same time, DeepMind announced Gemini 2.0, Genie 2, among others. The long-awaited OpenAI’s Sora is finally here, along with its rival from DeepMind, Veo-2 , as well as an update to one of my favorite smol models: Phi-4 has just been released. OpenAI also pushes the boundaries of test-time compute with o3 which tops the ARC-AGI benchmark. But at what cost? $5k/task. That’s right.
And just before we wrap up the year, we get DeepSeek-v3. It’s a stronger model than 3.5 Sonnet and 4o, but that’s not its biggest feat; it’s a 100% open source model, costs only 10% of the competitor’s price, and (this is the mind-blowing part, if it’s all true): they trained it for just $5.5mio on 2048 H800 GPUs for 2 months. For reference, this level of performance usually needs clusters closer to 16K GPUs (xAI’s Colossus has 100k). Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute) [Ref: Andrey Karpathy]. Last but not least is Byte Latent Transformers by Meta, which is very interesting; it operates directly on raw bytes of data, eliminating the need for tokenization.
1. Beyond Moore’s Laws: Chips, Quantum, and LEGOs
Nature isn’t classical, dammit, and if you want to make a simulation of nature, you’d better make it quantum mechanical.
— Richard Fenyman [1982]
For decades, we've been riding the wave of a self-fulfilling prophecy: Moore's Law (or should I say, Moore’s prediction?).
Since first coined in 1965 by Gordon Moore, the co-founder of Intel, this “law” has been the heartbeat of the semiconductor industry, pushing us to double the number of transistors on microchips roughly every two years. This is based on the observation that, for a given integrated circuit size, the number of transistors we could cram into it was proportional to the volume of an individual transistor.
And there's another observation: the number of people predicting the death of Moore's Law seems to be doubling every two years too! 😄 Although I'm afraid that joke won't last much longer.
![Moore's Law graphed vs real CPUs & GPUs 1965 - 2019 [OC] : r/dataisbeautiful](https://substackcdn.com/image/fetch/$s_!2VZH!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F90f44158-156a-4e16-bdef-63f07c4380d5_6529x4716.png "Moore's Law graphed vs real CPUs & GPUs 1965 - 2019 [OC] : r/dataisbeautiful")
The End of Moore’s Law (For Real)?
Yes, the increase in transistor density is decelerating. TSMC might be confident about squeezing out another 30 years, but we're talking about hitting a wall at the atomic level and battling with three interrelated forces: size, heat, and power. As transistors continue to shrink, Moore's Law is reaching its limits; cramming more and more onto a chip is getting tougher as the more tightly packed electrons will heat up a chip and cause meltdown unless cooled.

Another big challenge is on the manufacturing side. Currently, extreme ultraviolet (EUV) lithography is used for some key steps, but it faces limitations in alignment precision and the sheer costs in high-volume manufacturing (and when I say costly, I mean $380 million per unit). (Further reading: IBM)
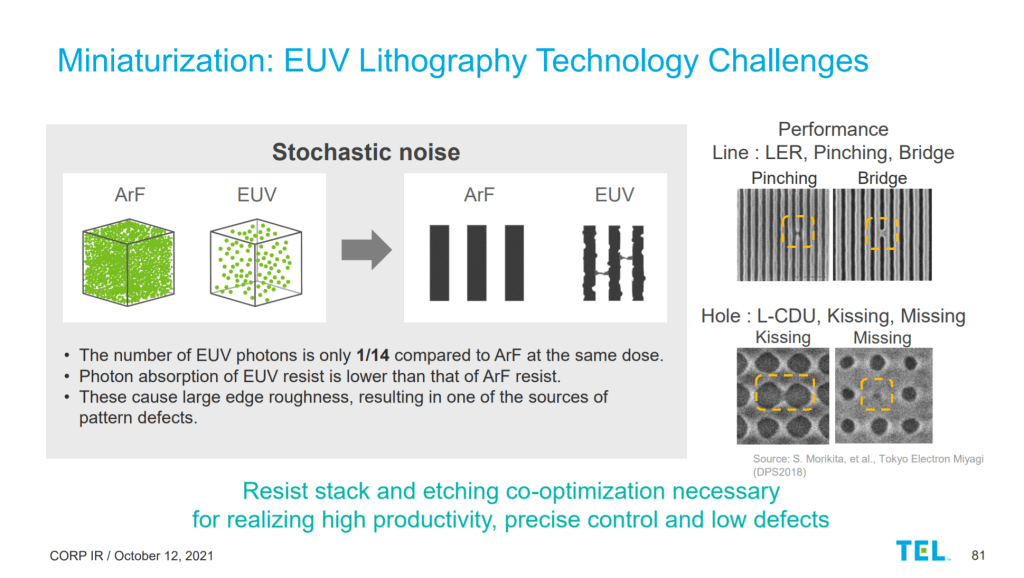
Manufacturing's a beast, but semiconductor manufacturing? it’s another league of its own. And keeping the law alive by e.g introducing new materials and complex 3D structures? That's like adding another head to the beast.
We do have another alternative i.e building chips atom-by-atom, like some kind of microscopic LEGO set1, which has been a long-standing dream for human. This bottom-up manufacturing include techniques like injection molding, 3D printing, direct self-assembly, and atomic manipulation. But this also come with its own set of challenges.
All in all, there are still many paths forward to continue performance scaling, which include: 1) New Material & Devices, 2) More Efficient Architectures & Packaging, 3) New Models of Computation. But historically speaking, walking down each of this path is a rather long journey. Take the fin field-effect transistor (FinFET) as an example, it took 10 years for an advance in basic device physics to reach mainstream use. So the lead-time and sustained R&D of one to two decades is expected for any path forward to really take off.
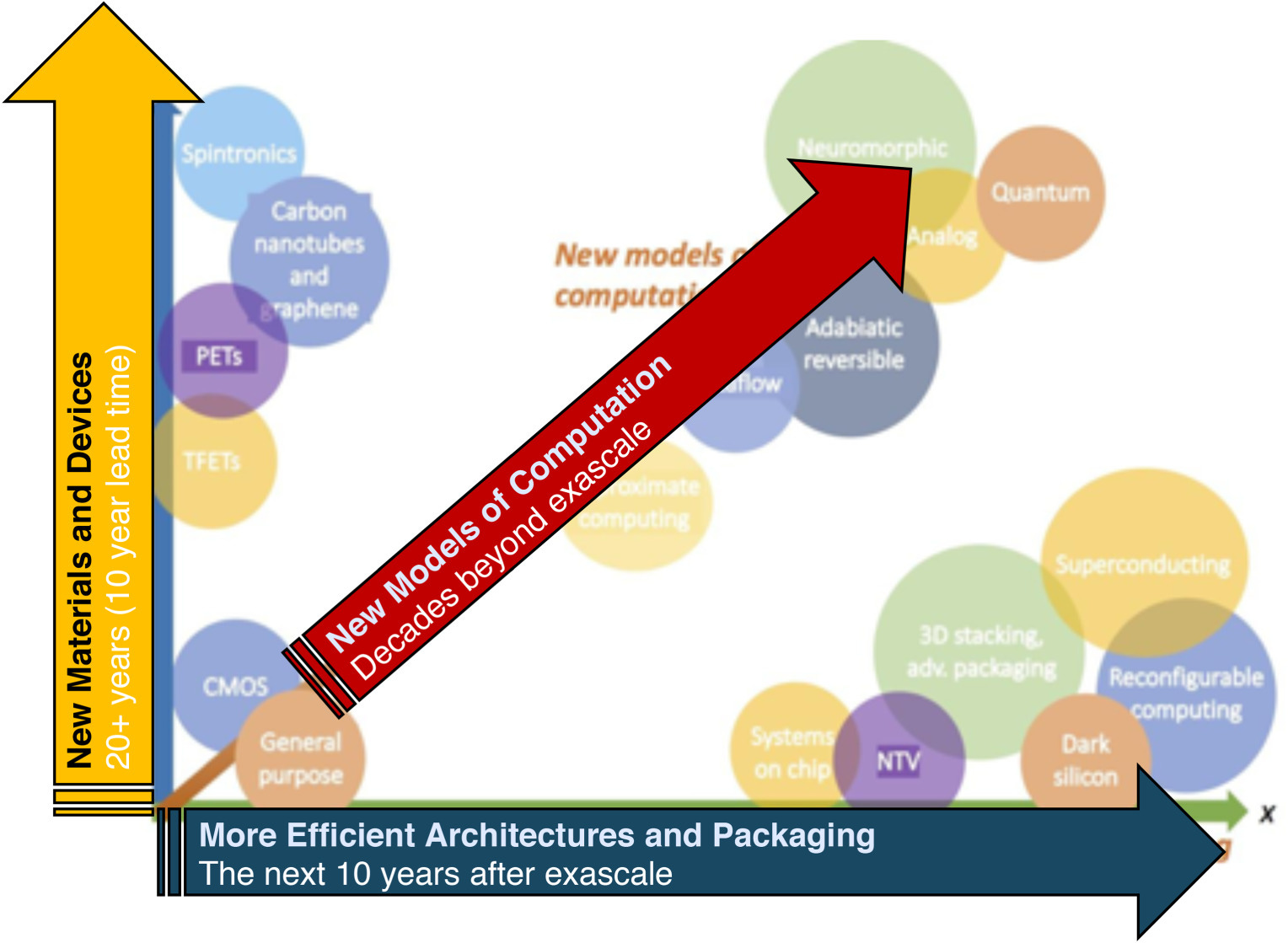
Hopefully we are still on track. But let’s say, worse comes to worst and we don’t find any new transistors and the pace of miniaturization hit a wall, then the demand for greater computing power can be met through architectural specialization. This means designing hardware optimized for specific tasks e.g: 1) Google’s Tensor Processing Unit (TPU) which accelerates the process for ML tasks; 2) the use of field-programmable gate arrays (FPGAs) in the Microsoft Cloud infrastructure 3) System-on-chips (SoC) for embedded, Internet of things (IoT) and smartphone applications. All of which were already pursuing specialization to good effect.

Broadcom's 3.5DXDSiP platform further illustrates this trend. By utilizing TSMC's CoWoS-L packaging technology, it achieves a high level of integration and interconnect density, resulting in significant performance gains. This technology enables a packaging size approximately 5.5 times larger than the reticle size, with a total area of 4,719 mm² and integrates logic ICs, up to 12 HBM3/HBM4 stacks, and additional I/O chips. To maximize performance, Broadcom suggests disintegrating the design of compute chiplets and stacking one logic chiplet on top of another in a face-to-face (F2F) manner using hybrid copper bonding (HCB).
One other notable alternative is the implementation of technique like SIMT (Single Instruction Multiple Threads), which has been incorporated by Nvidia into their GPUs starting with the "Volta" V100 in 2017. Subsequent models like the "Ampere" A100 (2020) and "Hopper" H100 (2022) have seen significant increases in transistor count and performance [54.4 bio transistors and 80 bio transistors, respectively]. The H100 achieved 80 billion transistors by integrating two adjacent chips in one package. Nvidia has also innovated with the GH200, which integrates ARM CPU cores to reduce CPU-to-GPU PCIe bottlenecks by utilizing Nvidia NVLink-C2C chip interconnects that result in 7x bandwidth increase and 5x power consumption reduction compared to PCIe. The H200, launched in late 2023, features 141 GB of HBM3E memory and a 4.8TB/s bandwidth. The latest iteration2, the B200, now incorporates 208 billion transistors distributed across a two-die chiplet. Looking ahead, TSMC aims to produce monolithic chips with 200 billion transistors and multi-die chiplets with 1 trillion transistors by 2030.

The Future of Computing (Might be): Quantum
The slowing of Moore’s Law highlights the limitations of classical computing, which relies on bits representing 0 or 1. One new type of computation, which actually dates back to the early 1990s, is the use of principles of quantum mechanics called quantum computing. It introduces a fundamentally different approach using qubits (or quantum bits).

Unlike classical bits, qubits can exist in a superposition of states, meaning it can be 0, 1, or a combination of both at the same time. This property, along with other quantum phenomena like entanglement, allows quantum systems to encode exponentially more information. Adding just one more qubit doubles the system’s capacity: one qubit can represent two states, two qubits four states, three qubits eight states, and so on. This exponential growth means that a system with 10 qubits can represent 1,024 states, while with 20 qubits we can manipulate roughly one million bits of information.
This is, as with Moore’s Law, exponential growth.

But unlike in classical computing where one bit of data has a physical location (e.g., memory addresses), the information in a quantum system isn’t stored in specific, individual physical spots. While the physical qubits themselves (e.g., superconducting loops, trapped ions, photons) occupy physical space, the information they encode is not localized to a single, easily addressable physical spot in the same way as classical bits.
Quantum algorithms like Shor's (for integer factorization) and Grover's (for database searching) demonstrate the potential for quantum computing to outperform classical methods in specific computational tasks. However, there are big challenges: scalability of building and controlling large numbers of qubits, quantum noise, and high operational costs. Current quantum devices still make too many errors. Even state-of-the-art quantum devices will typically experience at least one failure in every thousand operations. To achieve their potential, performance needs to improve dramatically (think about at least one in a million).
Quantum computing is not meant to be a universal replacement for classical computing and should be thought of as different in its capabilities, rather than “faster” in a generic sense. Although in extreme cases, computing time on classical computers for exponential problems, even with the most powerful supercomputers, could exceed the age of the Universe for practical problems.

Quantum computing is going through different stages of development since its inception. Currently, we're moving beyond what's known as the "Noisy Intermediate-Scale Quantum" (NISQ) era towards Quantum Utility (hopefully). Think of NISQ machines as the early, somewhat clunky computers of the quantum world. They've got a limited number of qubits, and they're prone to errors. However, they still offer the potential to surpass classical computers in certain tasks. This era has seen the rise of hybrid quantum-classical algorithms to optimize the computational power of NISQ devices amid noise and limited qubit coherence.
IBM's 1,000-qubit Condor processor is a milestone in quantum computing, but raw qubit count isn't everything. True "quantum utility" comes from reliable performance to tackle real-world problems. That's where their new Heron chip shines, boasting 133-156 qubits with record-low error rates. This marks a shift for IBM’s previous strategy of doubling qubit counts annually, towards prioritizing quality over quantity, and signals a move towards practical applications.
So, what's all the fuss about Willow?
On December 9th, 2024, Google made the news with its new 105-qubit superconducting quantum computer chip which reportedly can solve certain problems in 5 minutes that would take a classical supercomputer 10^25 years (if memory is an issue) and "only" ~300 million years if memory is not an issue. To give you a bit of perspective, since the Big Bang, the time elapsed has been only ~10^10 years.

It's tough to wrap our heads around these announcements and figure out what this "breakthrough" really means. While some interpretations, such as those mentioned in Google's blog, have even suggested connections to the concept of a multiverse, more grounded perspectives offer a different view. Physicist Sabine Hossenfelder states that the result of this calculation has no practical use and the consequences for everyday life are zero. And through his blog, Gil Kalai put a case against the quantum supremacy claim.
But here's the gist: Google's Willow processor, with its focus on error correction, is a well-deserved milestone (albeit somewhat overdue milestone, aligning with their own roadmap). Even though it has fewer qubits than their previous Condor chip or even Heron r2, Willow shows they're serious about improving qubit quality and reducing errors.
However, Google's latest quantum computing advancements, while impressive, are not entirely unexpected, especially for those who have been following experimental quantum computing at least since Google’s quantum supremacy milestone in 2019 with Sycamore. They've been steadily improving their technology over the past five years, increasing qubit count from ~53, coherence time by a factor of 5, and 2-qubit gate fidelity to roughly 99.7% (for controlled-Z gates) or 99.85% (for “iswap” gates) — an improvement from ~99.5% in 2019.
But they are not the only one who are making progress. How does it fare with the competition? Take a look at the below figure:
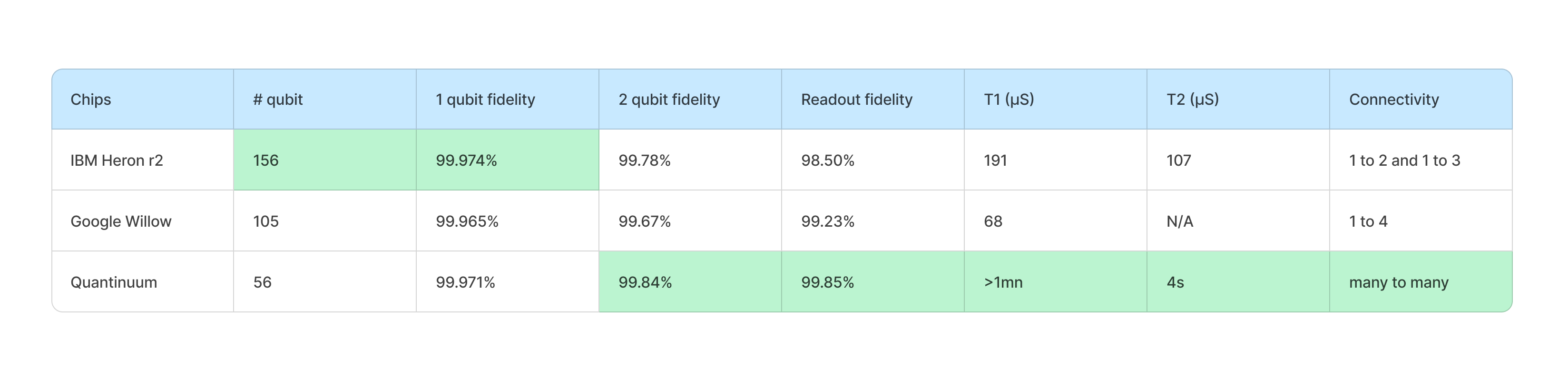
I recommend you to also read these pieces by Scott Aaronson and Olivier Ezratty.
2. World Model: Sora, Veo 2, Genie 2, Genesis
Remember back in March when we were talking about Sora, as a promising "world simulator"? Well, it's finally here. But..
… things aren't quite as they seemed. There's a bit of chatter online that the final release isn't as mind-blowing as the early previews, and that the physics are wonky. But hey, I can’t really complain. Just two years ago, AI struggled to generate even basic images, and now we can create entire video clips from text prompts, add our own images, and even refine the results.
However, now that Google has finally released the iteration of their text-to-video generation model: Veo-2, people begin to compare their results. Check out this side-by-side comparison and you’ll know which one we like better (Credits to Ruben Hassid).
One will argue that, for Sora, with its emphasis on diverse aspect ratios and creative storytelling, it will excel in generating imaginative and visually compelling videos [indeed, it’s very imaginative.. I mean look at those Flamingo dancing and tomatoes cutting video].
Veo 2, on the other hand, seem to be prioritizing realism and user control, offering high-resolution output and fine-grained control over cinematic parameters such as lens types, camera angles, and special effects. Google hasn’t released any technical details regarding Veo 2, but hopefully we can dissect it soon.
Generating Worlds
Beyond “simple” video generation, there’s a concept of “world models” (First coined by David Ha, Jürgen Schmidhuber. And yes, Schmidhuber does seem to invent everything]. Unlike systems that merely process data, allows AI to build a dynamic, multi-dimensional understanding of its environment a mental map for visualizing and interacting with the world, including the consequences of taking any action (e.g. jump, swim, etc.).
World Labs, a spatial intelligence company co-founded by AI pioneer Fei-Fei Li, unveiled an AI system that generates interactive 3D scenes from a single image. This system allows users to explore AI-generated scenes directly in a web browser, with the ability to move freely within the environment and interact with its elements.
Google DeepMind's Genie 2, the latest iteration of Genie (previously limited to 2D environments), takes things a step further. As a "foundation world model", it generates interactive 3D environments explorable and manipulable by both humans and AI agents. Using a single image or text prompt, Genie 2 creates immersive and responsive environments, maintaining consistent worlds for up to a minute, though most examples typically last 10-20 seconds (Credits to Google).
Genie 2 exhibits several emergent capabilities, including:
Long-horizon memory: Accurately renders previously unseen portions of the environment when they become visible.
Counterfactual generation: Simulates diverse trajectories from a single starting frame, enabling counterfactual training for agents.
Object affordances and interactions: Models interactions such as bursting balloons, opening doors, and explosive detonations.
NPCs: Simulates other agents and their interactions.
Physics-based effects: Models water, smoke, gravity, lighting (point and directional), reflections, bloom, and colored lighting.
And what’s even more interesting is that, Genie 2 can provide dynamic environments for training and evaluating embodied AI agents, making it a powerful tool for AI research and game development. Genie 2 has the potential to accelerate AI research by providing a flexible tool for experimentation and empowering developers to focus on creative and analytical tasks.

Genie 2 is an autoregressive latent diffusion model, trained on a large video dataset. After passing through an autoencoder, latent frames from the video are passed to a large transformer dynamics model, trained with a causal mask similar to that used by large language models.
At inference time, Genie 2 can be sampled in an autoregressive fashion, taking individual actions and past latent frames on a frame-by-frame basis. Google use classifier-free guidance to improve action controllability.
A Universal Physics Engine
Yeah, December has turned into an all-out sprint to simulate reality. Between Sora, Veo 2, and Genie, it feels like everyone’s scrambling to simulate the world. Another approach to simulate and generate the world is through physics-first. A team of avengers from 19 organizations assembled to create Genesis: physics simulation platform designed for general purpose Robotics, Embodied AI, & Physical AI applications.

What makes Genesis unique is its comprehensive approach to physics simulation. Built from the ground up, it's not just another physics engine – it's a universal platform that brings together multiple groundbreaking capabilities:
Ultra-Fast Python-Based Architecture
Astonishingly, despite being developed in pure Python, Genesis achieves speeds 10-80x faster than GPU-accelerated platforms like Isaac Gym and MJX
The numbers are mind-blowing: 43 million FPS for manipulation scenes (430,000x faster than real-time!)
Training robotic locomotion policies takes just 26 seconds on a single RTX4090
Comprehensive Physics Simulation Genesis integrates multiple state-of-the-art physics solvers:
MPM, SPH, FEM for complex material dynamics
Rigid Body and PBD for precise object interactions
Support for diverse materials: from cloth and liquids to robot muscles and deformables
Examples of "4D dynamical and physical" worlds that Genesis created from text prompts:
I'm particularly excited about Genesis's potential impact on robotics and AI research. Being open source (available at https://github.com/Genesis-Embodied-AI/Genesis) means we'll likely see fascinating applications and extensions from the community.

As shown in the above figure. Each approach brings something unique to the table, and I'm honestly thrilled to see how they'll push each other forward.
Charts that Caught My Attention
1. Electric vehicle battery prices are expected to fall almost 50% by 2026
In summary, there are two main drivers: technological innovation that brings about 30% higher energy density and lower cost. The other is the continued downturn in battery metal prices: lithium, cobalt (and nearly 60% of the cost of batteries is from metals).

2. The Golden Age of Antibiotics
Hint: it was in the 40s-60s.
. Created by Saloni Dattani for Our World in Data.")
3. X Added a lot of Features in 2024
They sure became very productive since Elon Musk took over. What about in 2025?

Other Interesting Reads
What was the Golden Age of Antibiotics, and how can we spark a new one? by Our World in Data
Ask Ethan: Do gravitons need to exist? by Ethan Siegel
Cognitive load is what matters by minds.md
References
Wong, H. & Kakushima, K. On the Vertically Stacked Gate-All-Around Nanosheet and Nanowire Transistor Scaling beyond the 5 nm Technology Node. Nanomaterials 12, 1739 (2022).
Drechsler, R. & Wille, R. Reversible Circuits: Recent Accomplishments and Future Challenges for an Emerging Technology. in Progress in VLSI Design and Test (eds. Rahaman, H., Chattopadhyay, S. & Chattopadhyay, S.) vol. 7373 383–392 (Springer Berlin Heidelberg, Berlin, Heidelberg, 2012).
https://www2.physics.ox.ac.uk/sites/default/files/ErrorCorrectionSteane06.pdf
Gill, S. S. et al. Quantum Computing: Vision and Challenges. Preprint at https://doi.org/10.48550/arXiv.2403.02240 (2024).
Acharya, R. et al. Quantum error correction below the surface code threshold. Nature 1–3 (2024) doi:10.1038/s41586-024-08449-y.
Roffe, J. Quantum Error Correction: An Introductory Guide. Preprint at https://doi.org/10.48550/arXiv.1907.11157 (2019).
Phalak, K., Chatterjee, A. & Ghosh, S. Quantum Random Access Memory For Dummies. Preprint at http://arxiv.org/abs/2305.01178 (2023).
Mohseni, M. et al. How to Build a Quantum Supercomputer: Scaling Challenges and Opportunities. Preprint at https://doi.org/10.48550/arXiv.2411.10406 (2024).
AbuGhanem, M. IBM Quantum Computers: Evolution, Performance, and Future Directions. Preprint at https://doi.org/10.48550/arXiv.2410.00916 (2024).
https://www.oezratty.net/wordpress/2024/inside-google-willow
https://scottaaronson.blog/
Footnotes
Speaking of LEGO, ASML sells LEGO model of their most advanced chip machine to workers.
Rumor has it that Santa Huang is blessing everyone with his christmas present: GB300 and B300.